I've got a simple script to remove characters from the left & right of a string containing a datetime value. The reason for this is that there are unnecessary characters on each side of the actual value I want.
It works by looping through all items in a column (called Time), removing the characters & then replacing the old value with the new one.
This works for the most part, excluding weirdly the first two rows in the dataframe.
For some odd reason, in the .csv files I am using, the 'Time' column has the values as strings, whereas the 'Closing Time' throws an error unless I specify they are strings, even though they have the exact same structure.
Here is a screenshot of what the input fields on the .csv look like:
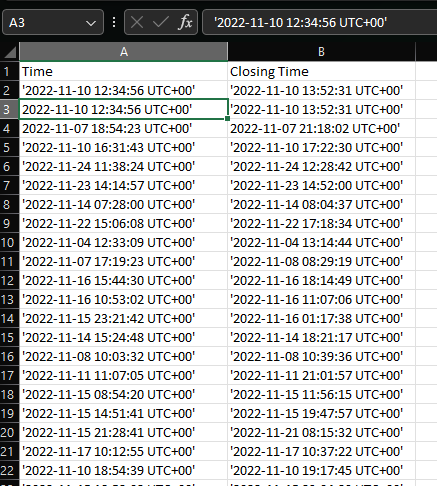
Please note: the second row, first value not having a speech mark before it is a weird excel thing & the actual value has it on as seen above in the same screenshot.
Here is the code I am using:
import pandas as pd
df = pd.read_csv("file.csv") # reading file
for item in df['Time']:
item2 = item[1:]
item3 = item2[:-8]
df.replace(item, item3, inplace=True)
for item21 in df['Closing Time']:
item22 = str(item21)[1:]
item23 = str(item22)[:-8]
df.replace(item21, item23, inplace=True)
print(df['Closing Time'])
print(df['Time'])
input("\nScript executed successfully | Press ENTER to Exit. ")
Here is the output:
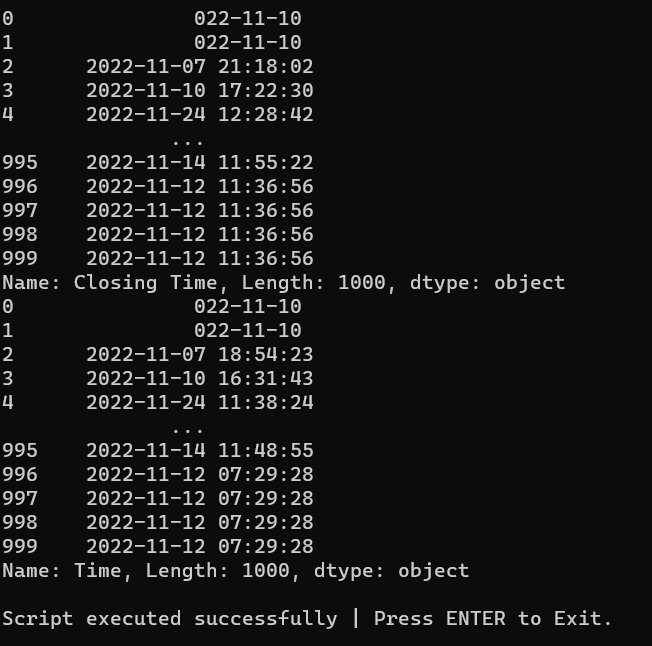
Is this a bug? Because I see no reason why the first two columns specifically are coming out as different to the rest.
CodePudding user response:
If you only want to extract the timestamps as string, I would suggest using regex. Furthermore, iterating over a dataset with a for loop is highly inefficient (and with big datasets, you will notice the slowness); I suggest using an str.extract function:
import pandas as pd
df = pd.read_csv("file.csv") # reading file
match_string = r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})'
df['Time'] = df['Time'].str.extract(match_string)
df['Closing Time'] = df['Closing Time'].str.extract(match_string)
print(df['Closing Time'])
print(df['Time'])
input("\nScript executed successfully | Press ENTER to Exit. ")