I suppose both the pandas value_counts() and histogram gives the frequency of an item. I have a case where this is different. When I plot a histogram, I get two peaks as shown below,
d = pd.read_csv('sample.csv')
d.hist()
d['value'].value_counts().nlargest(3)
200000000.0 906
20.0 219
10.0 158
Name: value, dtype: int64
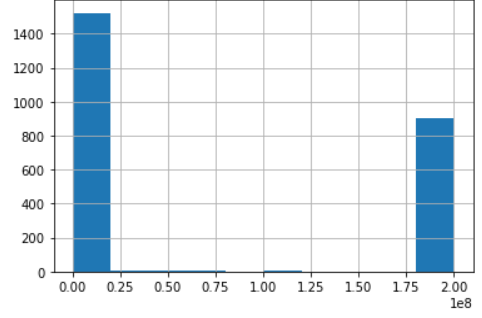
But when I use value_counts(), I only get the value 200000000 as the most occurring one, but instead it should be something around 0.02. Can someone explain what exactly happens here. The sample data that I used is 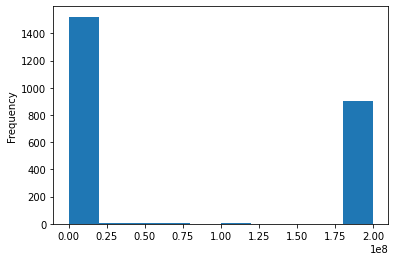
The (approximate) equivalent using a 
Output of pd.cut(df['value'], bins=10).value_counts(sort=False):
(-199999.996, 20000000.004] 1523
(20000000.004, 40000000.003] 5
(40000000.003, 60000000.003] 9
(60000000.003, 80000000.002] 5
(80000000.002, 100000000.002] 0
(100000000.002, 120000000.002] 8
(120000000.002, 140000000.001] 0
(140000000.001, 160000000.001] 0
(160000000.001, 180000000.0] 0
(180000000.0, 200000000.0] 906
Name: value, dtype: int64
CodePudding user response:
they are the same thing if you checked the csv file you will find that 200000000.0 is exactly 906 and that is what they both showing but in the histogram they used apprev to the numbers 1e8