Environment: I'm using Databricks with spark 3.3.0 and Python 3.
Problem trying to solve: I'm trying to replace some of the attribute values of a json struct column. I have a dataframe that contains a struct type column that has the following json content structure:
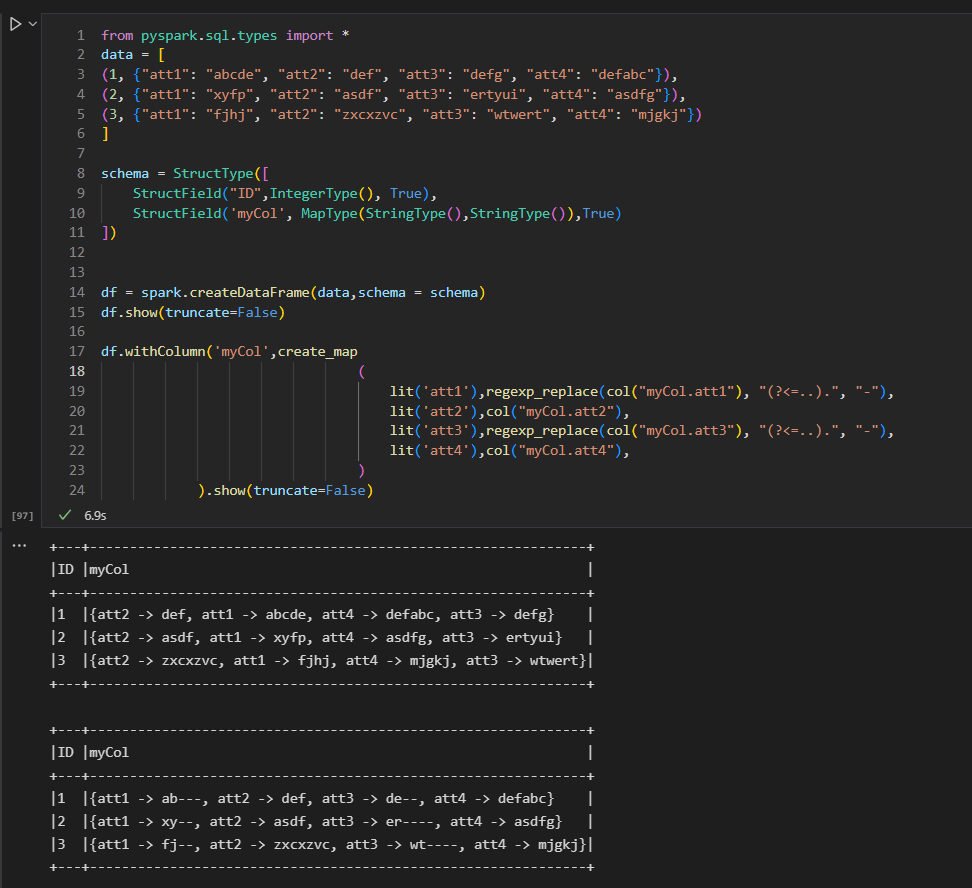
| ID | myCol |
|---|---|
| 1 | {"att1": "abcde", "att2": "def", "att3": "defg", "att4": "defabc"} |
| 2 | {"att1": "xyfp", "att2": "asdf", "att3": "ertyui", "att4": "asdfg"} |
| 3 | {"att1": "fjhj", "att2": "zxcxzvc", "att3": "wtwert", "att4": "mjgkj"} |
The dataframe contains thousands of records, I'm a bit new to spark programming so I've been having a hard time to come up with a way to replace the values of "att1" and "att3" in all rows in the dataframe with the same value but leaving only the first two characters and masking the rest, i.e from the example above:
Expected Output:
| ID | myCol |
|---|---|
| 1 | {"att1": "ab---", "att2": "def", "att3": "de--", "att4": "defabc"} |
| 2 | {"att1": "xy--", "att2": "asdf", "att3": "er----", "att4": "asdfg"} |
| 3 | {"att1": "fj--", "att2": "zxcxzvc", "att3": "wt----", "att4": "mjgkj"} |
I was looking into maybe using org.apache.spark.sql.functions.regexp_replace but i don't know how to replace only part of the value, i.e from "abcde" to "ab---", i've looked at similar examples online except every single one of them replaces the entire value and the value is known beforehand such as this one