I have a spark SQL query as below:
with xxx as (
select pb_id, pb_name, req_id, level, t_val_id_path
from(
select pb_id, pb_name, req_id, explode(req_vals) as t_id
from A
where dt = '2022-11-20') a
join (
select t_val_id, level, t_val_id_path
from B
where dt = '2022-11-20')b
on a.t_id = b.t_val_id)
select distinct
pb_id, req_id, -1 as l1, -1 as l2, -1 as l3
from xxx
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, -1 as l2, -1 as l3
from xxx
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, t_val_id_path[1] as l2, -1 as l3
from xxx
where level > 0
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, if(level > 0, t_val_id_path[1], 1) as l2, if(level > 1, t_val_id_path[2], 1) as l3
from xxx;
In Azure Databricks, the SQL query plan is below:
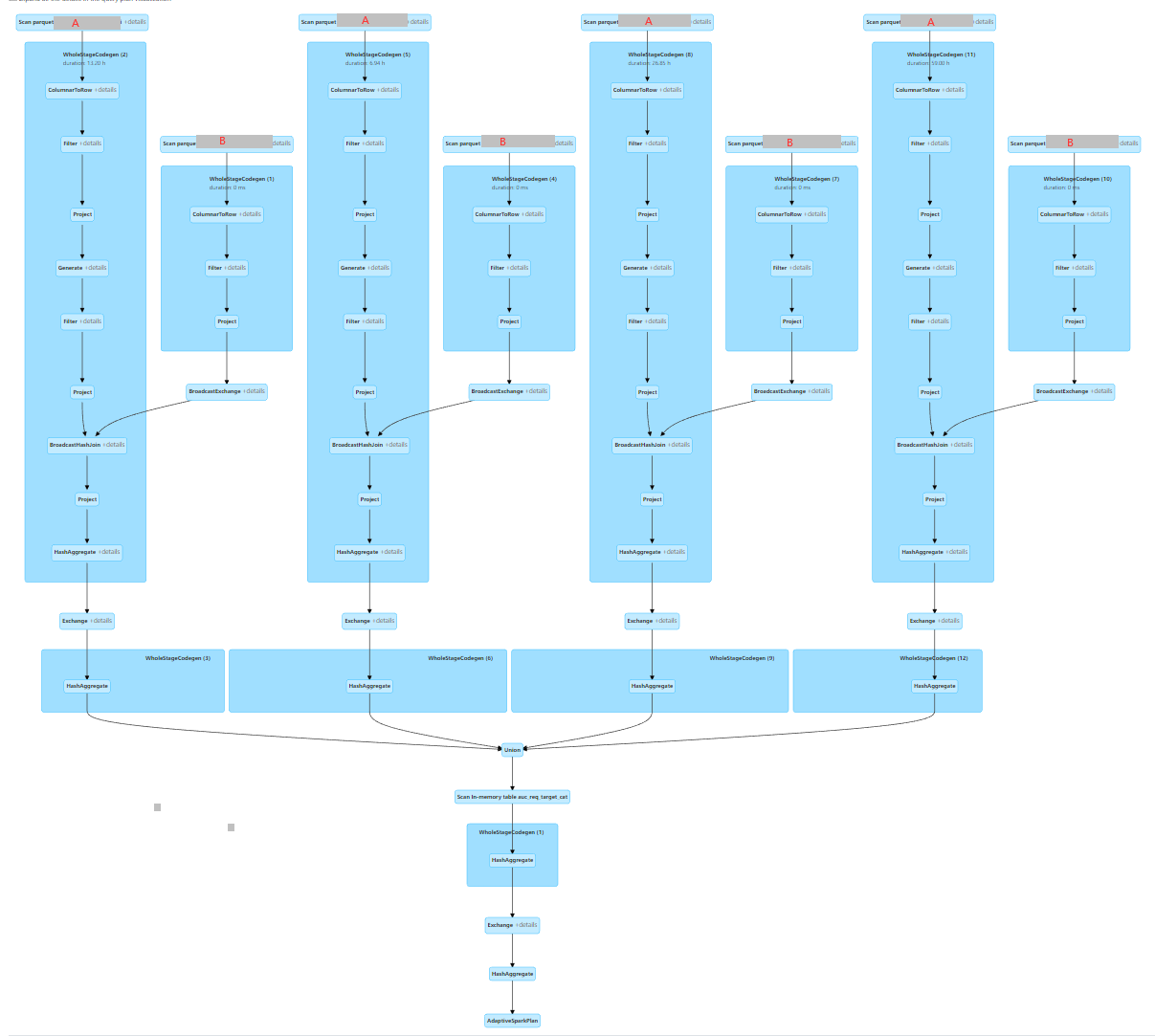
Question: From the SQL script it may just read table A & B of hive table. But in the query plan, we could see that we would read A 4 times and B 4 times. Is it possible that we read A & B just once and then do the filter and transformation in memory instead to read it again and again?
CodePudding user response:
Maybe you can try to cache your xxx table. You can use cache also in sql, not only in df api
https://spark.apache.org/docs/3.0.0-preview/sql-ref-syntax-aux-cache-cache-table.html
So imo it may look like this:
spark.sql("CACHE TABLE xxx as (
select pb_id, pb_name, req_id, level, t_val_id_path
from(
select pb_id, pb_name, req_id, explode(req_vals) as t_id
from A
where dt = '2022-11-20') a
join (
select t_val_id, level, t_val_id_path
from B
where dt = '2022-11-20')b
on a.t_id = b.t_val_id)")
spark.sql(
"select distinct
pb_id, req_id, -1 as l1, -1 as l2, -1 as l3
from xxx
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, -1 as l2, -1 as l3
from xxx
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, t_val_id_path[1] as l2, -1 as l3
from xxx
where level > 0
union all
select distinct
pb_id, req_id, t_val_id_path[0] as l1, if(level > 0, t_val_id_path[1], 1) as l2, if(level > 1, t_val_id_path[2], 1) as l3
from xxx"
)