I have a PySpark dataframe with values and dictionaries that provide a textual mapping for the values. Not every row has the same dictionary and the values can vary too.
| value | dict |
| -------- | ---------------------------------------------- |
| 1 | {"1": "Text A", "2": "Text B"} |
| 2 | {"1": "Text A", "2": "Text B"} |
| 0 | {"0": "Another text A", "1": "Another text B"} |
I want to make a "status" column that contains the right mapping.
| value | dict | status |
| -------- | ------------------------------- | -------- |
| 1 | {"1": "Text A", "2": "Text B"} | Text A |
| 2 | {"1": "Text A", "2": "Text B"} | Text B |
| 0 | {"0": "Other A", "1": "Other B"} | Other A |
I have tried this code:
df.withColumn("status", F.col("dict").getItem(F.col(value"))
This code does not work, I am aware you cannot access a row value like this.
With a hard coded value, like "2", the same code does provide an output, but of course not the right one:
df.withColumn("status", F.col("dict").getItem("2"))
Could someone help me with getting the right mapped value in the status column?
CodePudding user response:
Hope this helps.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import json
if __name__ == '__main__':
spark = SparkSession.builder.appName('Medium').master('local[1]').getOrCreate()
df = spark.read.format('csv').option("header","true").option("delimiter","|").load("/Users/dshanmugam/Desktop/ss.csv")
schema = StructType([
StructField("1", StringType(), True)
])
def return_value(data):
key = data.split('-')[0]
value = json.loads(data.split('-')[1])[key]
return value
returnVal = udf(return_value)
df_new = df.withColumn("newCol",concat_ws("-",col("value"),col("dict"))).withColumn("result",returnVal(col("newCol")))
df_new.select(["value","result"]).show(10,False)
Result:
----- --------------
|value|result |
----- --------------
|1 |Text A |
|2 |Text B |
|0 |Another text A|
----- --------------
I am using UDF. You can try with some other options if performance is a concern.
CodePudding user response:
Here are my 2 cents
Create the dataframe by reading from CSV or any other source (in my case it is just static data)
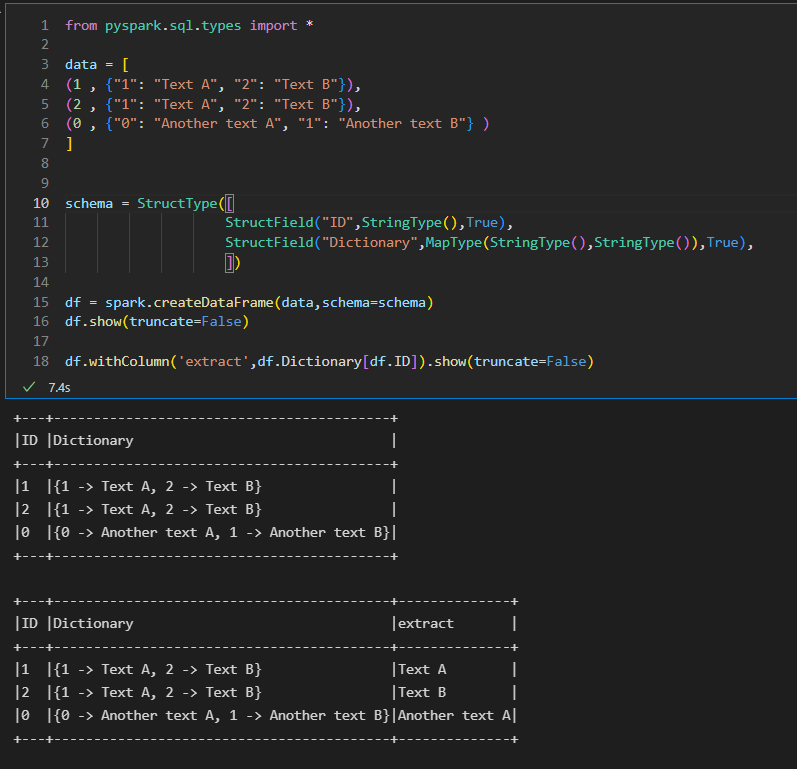
from pyspark.sql.types import * data = [ (1 , {"1": "Text A", "2": "Text B"}), (2 , {"1": "Text A", "2": "Text B"}), (0 , {"0": "Another text A", "1": "Another text B"} ) ] schema = StructType([ StructField("ID",StringType(),True), StructField("Dictionary",MapType(StringType(),StringType()),True), ]) df = spark.createDataFrame(data,schema=schema) df.show(truncate=False)Then directly extract the dictionary value based on the id as a key.
df.withColumn('extract',df.Dictionary[df.ID]).show(truncate=False)
Check the below image for reference: