Here is the example data I am working with. What I am trying to accomplish is 1) subtract b column from column a and 2) create the C column in front of a and b columns. I would like to loop through and create the C column for x, y and z.
import pandas as pd
df = pd.DataFrame(data=[[100,200,400,500,111,222], [77,28,110,211,27,81], [11,22,33,11,22,33],[213,124,136,147,54,56]])
df.columns = pd.MultiIndex.from_product([['x', 'y', 'z'], list('ab')])
print (df)
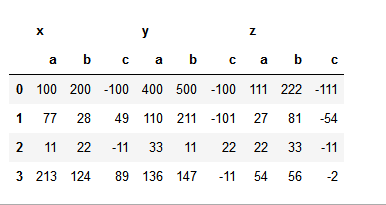
Below is what I am trying to get.
CodePudding user response:
Use DataFrame.xs for select second levels with avoid remove first level with drop_level=False, then use rename for same MultiIndex, subtract and add to original with concat, last use DataFrame.sort_index:
dfa = df.xs('a', axis=1, level=1, drop_level=False).rename(columns={'a':'c'})
dfb = df.xs('b', axis=1, level=1, drop_level=False).rename(columns={'b':'c'})
df = pd.concat([df, dfa.sub(dfb)], axis=1).sort_index(axis=1)
print (df)
x y z
a b c a b c a b c
0 100 200 -100 400 500 -100 111 222 -111
1 77 28 49 110 211 -101 27 81 -54
2 11 22 -11 33 11 22 22 33 -11
3 213 124 89 136 147 -11 54 56 -2
With loop select columns by tuples, subtract Series and last use DataFrame.sort_index:
for c in df.columns.levels[0]:
df[(c, 'c')] = df[(c, 'a')].sub(df[(c, 'b')])
df = df.sort_index(axis=1)
print (df)
x y z
a b c a b c a b c
0 100 200 -100 400 500 -100 111 222 -111
1 77 28 49 110 211 -101 27 81 -54
2 11 22 -11 33 11 22 22 33 -11
3 213 124 89 136 147 -11 54 56 -2
CodePudding user response:
a = df.xs('a', level=1, axis=1)
b = df.xs('b', level=1, axis=1)
df1 = pd.concat([a.sub(b)], keys=['c'], axis=1).swaplevel(0, 1, axis=1)
df1
x y z
c c c
0 -100 -100 -111
1 49 -101 -54
2 -11 22 -11
3 89 -11 -2
then at first concat df and df1 , next sort
pd.concat([df, df1], axis=1).sort_index(axis=1)
other way
use stack and unstack
df.stack(level=0).assign(c=lambda x: x['b'] - x['a']).stack().unstack([1, 2])
result:
x y z
a b c a b c a b c
0 100 200 100 400 500 100 111 222 111
1 77 28 -49 110 211 101 27 81 54
2 11 22 11 33 11 -22 22 33 11
3 213 124 -89 136 147 11 54 56 2