library(data.table)
library(dplyr)
A <-data.frame(V1=c("Amy", 1:6), V2=c("Grade", 1:6), V3=c("level", LETTERS[1:6]))
B <-data.frame(V1=c("Mike", 1:6), V2=c("Grade", 1:6), V3=c("level", LETTERS[1:6]))
C <-data.frame(V1=c("Kevin", 1:6), V2=c("Grade", 1:6), V3=c("level", LETTERS[1:6]))
D <-data.frame(V1=c("Grace", 1:6), V2=c("Grade", 1:6), V3=c("level", LETTERS[1:6]))
df <- A %>% rbind(B, C, D) %>% setnames(c("V1", "V2", "V3"), c("ID", "Grade", "level"))
I have 4 dataframe need to merge, the code above will keep value what I want to remove. I want ask about maybe have more effective way?
I want to replace Grade and level by NA or space.
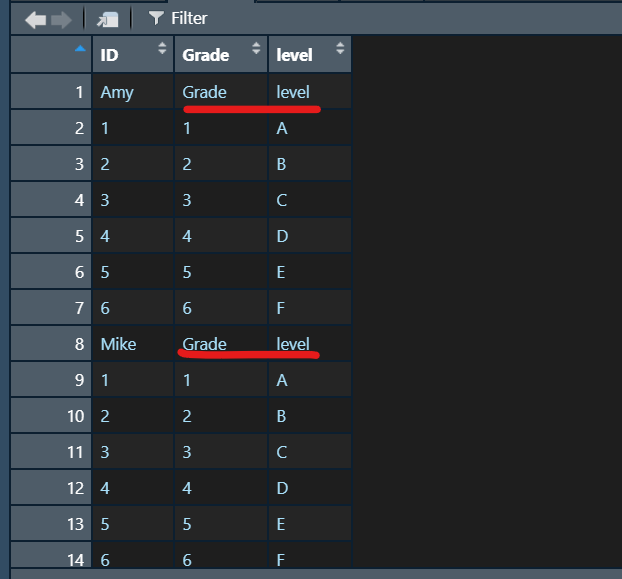
CodePudding user response:
I don't understand your question, but, assuming you want to keep the structure you show in the image, and you only want to replace the values indicated by NA or a white space (" ") you can first locate the position where these values are and assign by the character you want:
df[which(df=="Grade" | df == "level", arr.ind = T)] <- " "
You can use white space (" ") or NA. The output is:
> df
ID Grade level
1 Amy
2 1 1 A
3 2 2 B
4 3 3 C
5 4 4 D
6 5 5 E
7 6 6 F
8 Mike
9 1 1 A
10 2 2 B
11 3 3 C
12 4 4 D
13 5 5 E
14 6 6 F
15 Kevin
16 1 1 A
17 2 2 B
18 3 3 C
19 4 4 D
20 5 5 E
21 6 6 F
22 Grace
23 1 1 A
24 2 2 B
25 3 3 C
26 4 4 D
27 5 5 E
28 6 6 F
>
CodePudding user response:
Consider turning the name into a column. It'll probably be better for further analysis.
library(dplyr)
library(tidyr)
library(janitor) # Handy row_to_names function
list(A, B, C, D) |>
lapply(\(x) row_to_names(x, row_number = 1)) |>
Reduce(bind_rows, x = _) |>
pivot_longer(-c(Grade, level), values_drop_na = TRUE, values_to = "ID")
Output:
# A tibble: 24 × 4
Grade level name ID
<chr> <chr> <chr> <chr>
1 1 A Amy 1
2 2 B Amy 2
3 3 C Amy 3
4 4 D Amy 4
5 5 E Amy 5
6 6 F Amy 6
7 1 A Mike 1
8 2 B Mike 2
9 3 C Mike 3
10 4 D Mike 4
11 5 E Mike 5
12 6 F Mike 6
13 1 A Kevin 1
14 2 B Kevin 2
15 3 C Kevin 3
16 4 D Kevin 4
17 5 E Kevin 5
18 6 F Kevin 6
19 1 A Grace 1
20 2 B Grace 2
21 3 C Grace 3
22 4 D Grace 4
23 5 E Grace 5
24 6 F Grace 6