I have example data as follows:
library(data.table)
datA <- fread("ID somevar
NA 4
NA 3
2 5")
datB <- fread("ID somevar
7 4
NA 3
NA 5")
dat_list <- list(datA, datB)
In dat_list I would like to replace all NA's in the ID column with a new ID-number.
I would like this number to be unique and start at 100. I thought of something like this:
for (i in seq_along(dat_list)){
temp <- dat_list[[i]]
count_of_seq <- sum(is.na(temp$ID))
sequence_dat <- seq(100, 100 count_of_seq)
temp <- setDT(temp)[is.na(ID), ID:=sequence_dat[i]]
}
But this does not work because, it uses only one number of the sequence for each list:
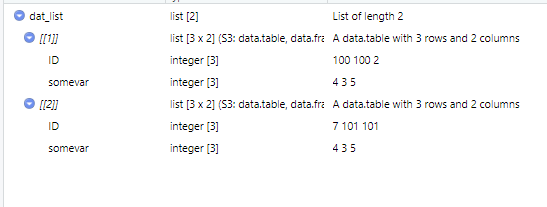
How should I do this properly?
Desired output:
library(data.table)
datA <- fread("ID somevar
100 4
101 3
2 5")
datB <- fread("ID somevar
7 4
102 3
103 5")
dat_list <- list(datA, datB)
CodePudding user response:
One dplyr option could be:
dat_list %>%
bind_rows(., .id = "dataset_ID") %>%
mutate(ID = ifelse(is.na(ID), 99 cumsum(is.na(ID)), ID)) %>%
group_split(dataset_ID, .keep = FALSE)
[[1]]
# A tibble: 3 × 2
ID somevar
<dbl> <int>
1 100 4
2 101 3
3 2 5
[[2]]
# A tibble: 3 × 2
ID somevar
<dbl> <int>
1 7 4
2 102 3
3 103 5
CodePudding user response:
In base R:
id <- 99
for (i in seq_along(dat_list)) {
nas <- is.na(dat_list[[i]]$ID)
dat_list[[i]]$ID[nas] <- id seq_len(sum(nas))
id <- id sum(nas)
}
dat_list
# [[1]]
# ID somevar
# 1: 100 4
# 2: 101 3
# 3: 2 5
#
# [[2]]
# ID somevar
# 1: 7 4
# 2: 102 3
# 3: 103 5