Suppose I have ABC in cell A1 and XaA in cell B1.
Taking into account upper and lower case, I would like to recognize that A is present in both strings.
Below is the formula I tried using:
=INDEX(FLATTEN(FILTER(FLATTEN(FILTER(REGEXEXTRACT(TO_TEXT(E1),
REPT("(.)", LEN(E1))),REGEXEXTRACT(TO_TEXT(E1),
REPT("(.)", LEN(E1)))<>"")),
FLATTEN(FILTER(REGEXEXTRACT(TO_TEXT(E1),
REPT("(.)", LEN(E1))),REGEXEXTRACT(TO_TEXT(E1),
REPT("(.)", LEN(E1)))<>""))<>"")&""&TRANSPOSE
(FILTER(FLATTEN(FILTER(REGEXEXTRACT(TO_TEXT(E2),
REPT("(.)", LEN(E2))),REGEXEXTRACT(TO_TEXT(E2),
REPT("(.)", LEN(E2)))<>"")), FLATTEN(FILTER(REGEXEXTRACT(TO_TEXT(E2),
REPT("(.)", LEN(E2))),REGEXEXTRACT(TO_TEXT(E2),
REPT("(.)", LEN(E2)))<>""))<>""))))
But it didnt work.
How can I do this using Excel or Google Sheets function?
Thank you.
CodePudding user response:
another approach... (handy if you have characters that needs to be escaped in regex)
if you untangle each:
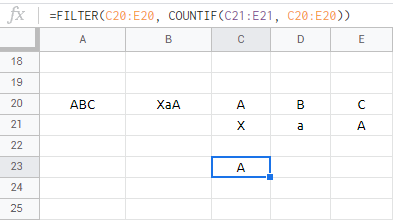
=REGEXEXTRACT(A20, REPT("(.)", LEN(A20)))
then you can filter it:
=FILTER(C20:E20, COUNTIF(C21:E21, C20:E20))
in one go:
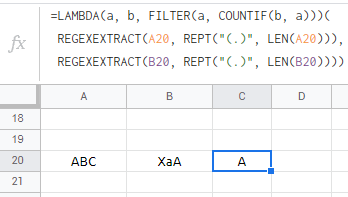
=LAMBDA(a, b, FILTER(a, COUNTIF(b, a)))(
REGEXEXTRACT(A20, REPT("(.)", LEN(A20))),
REGEXEXTRACT(B20, REPT("(.)", LEN(B20))))
UPDATE
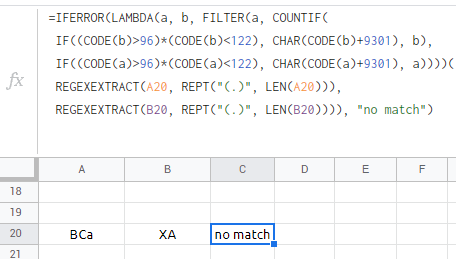
to differentiate b/n lower & upper case try the spectrum shift:
=IFERROR(LAMBDA(a, b, FILTER(a, COUNTIF(
IF((CODE(b)>96)*(CODE(b)<122), CHAR(CODE(b) 9301), b),
IF((CODE(a)>96)*(CODE(a)<122), CHAR(CODE(a) 9301), a))))(
REGEXEXTRACT(A20, REPT("(.)", LEN(A20))),
REGEXEXTRACT(B20, REPT("(.)", LEN(B20)))), "no match")
CodePudding user response:
Use regexmatch() and regexextract(), like this:
=regexmatch( B1, join( "|", unique( transpose( regexextract(A1, rept("(.)", len(A1))) ) ) ) )
In the event you want to list the matching characters instead of just getting a true/false result, or if the value in A1 may contain one or more special characters .* ?^${}()|[]\, use this longer formula:
=lambda(
a, b,
iferror(
filter( b,
regexmatch( b,
join( "|",
regexreplace(
unique(transpose(a)),
"[.* ?^${}()|[\]\\]", "\\$0"
)
)
)
),
"(no matches)"
)
)(
regexextract(A1, rept("(.)", len(A1))),
regexextract(B1, rept("(.)", len(B1)))
)