I have a set of data with multiple rows (>1000) containing tuples of words. I wanted to remove words that only appear once across all rows. Here is an example of the data...
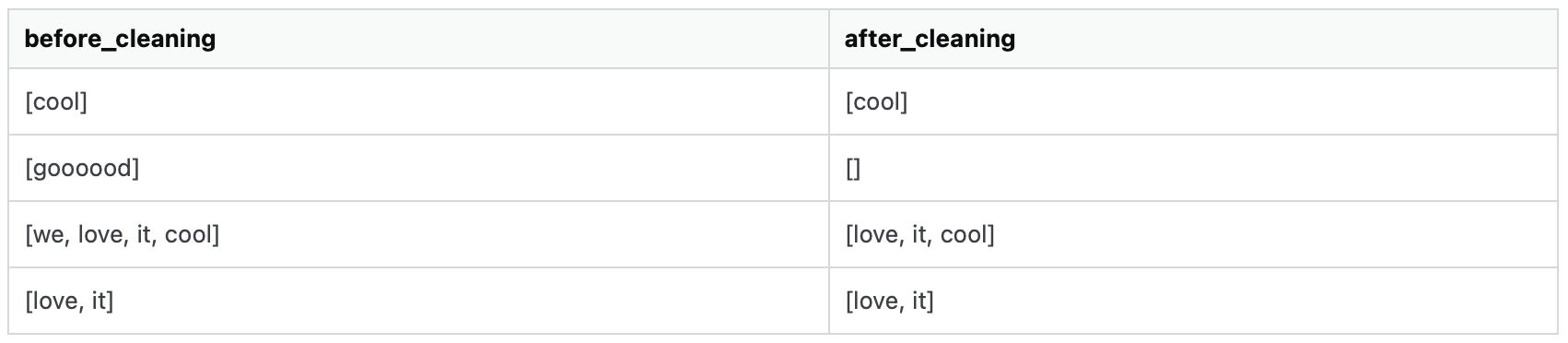
As you can see, "gooooood" and "we" is removed as the words only appear once across all rows. Could you help me solve this?
CodePudding user response:
Use collections.Counter and itertools.chain, a set and a list comprehension:
from collections import Counter
from itertools import chain
keep = {k for k,v in Counter(chain.from_iterable(df['before_cleaning'])).items()
if v>1}
# {'cool', 'it', 'love'}
df['after_cleaning'] = [[x for x in l if x in keep]
for l in df['before_cleaning']]
Output:
before_cleaning after_cleaning
0 [cool] [cool]
1 [good] []
2 [we, love, it, cool] [love, it, cool]
3 [love, it] [love, it]
Pandas alternative to create the set:
keep = set(df['before_cleaning'].explode().value_counts().loc[lambda x: x>1].index)
CodePudding user response:
You use lambda fun, and inside you can loop over each row list and check if count is more than 1 or not.
Code;
df['after'] = df['before'].apply(lambda row: [i for i in row if sum(list(df['before']),[]).count(i)>1])