I know the title is not clear enough. Here is the details. I need to parse something like below:
Client->iFrame.Initialise() {
res = Server.loadStaticResource()
if (res.status == 404 || res.status == 503) { <1>
throw Error()
}
}
== Initialisation done! == <2>
Client->iFrame.load(data) {
moreStatements()
}
It is a Java-like syntax, except that we support a Divider (shown as == Initialisation done! == in the example). Note that:
- both <1> and <2> uses
==. - It is treated as a Divider only if it appears at the beginning of the line (after spaces removed).
- Any character can be used between the starting
==and ending==except for changelines. - There could be more
=in the Divider component, such as=== 3 equals ===.
How should I implement that?
To add more context, this is to be used to render a sequence diagram like below. It is an opensource project and can be found here: 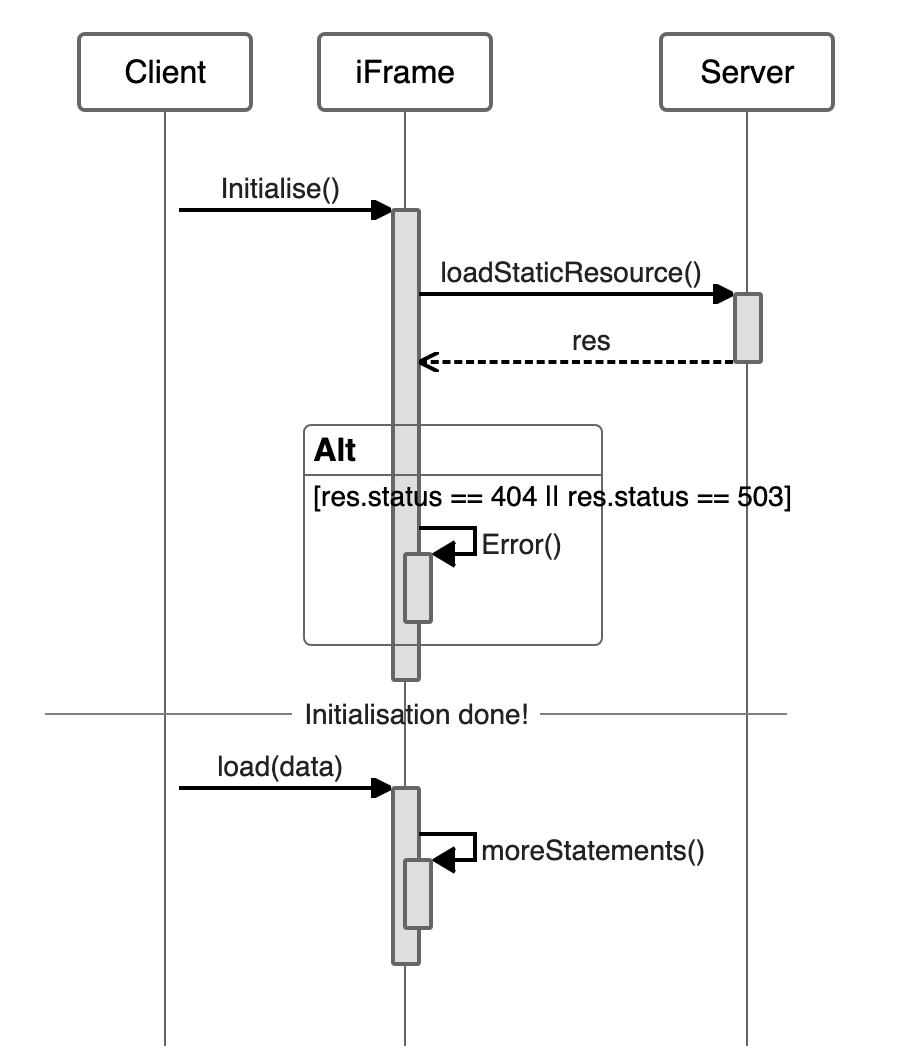
What I have tried?
I was looking for a way to use lookahead in the Lexer, but could not find any good examples. I am currently limiting the content between starting == and ending == to ONE word only.
My implementation is here:
- The parser: https://github.com/ZenUml/core/blob/b84c9ca0a6d023c5e520bf83a225e4931db134fc/src/g4/sequenceParser.g4#L88-L89
- The lexer: https://github.com/ZenUml/core/blob/main/src/g4/sequenceLexer.g4
CodePudding user response:
OK, here's the answer evolved from the question and comments, and from my experience writing little parsers for a long time.
Rule 1: find a way to cheat
In the case of ambiguities like in this question, looking for a solution in the lexer can be a useful avenue to explore. In this case, because newlines apparently have some degree of meaning, introducing a token that matches a newline followed by a couple of = signs means that the parser sees a token ("newline equal equal") that directly indicates the start of that production.
The particular "cheat" is a \n== token, so that the grammar can have that as a separator or statement start (whatever makes sense). If it appears at a weird point in the grammar somehow, the parser can throw an error that says "unexpected start of the == thing" because it knows that's what's going on.