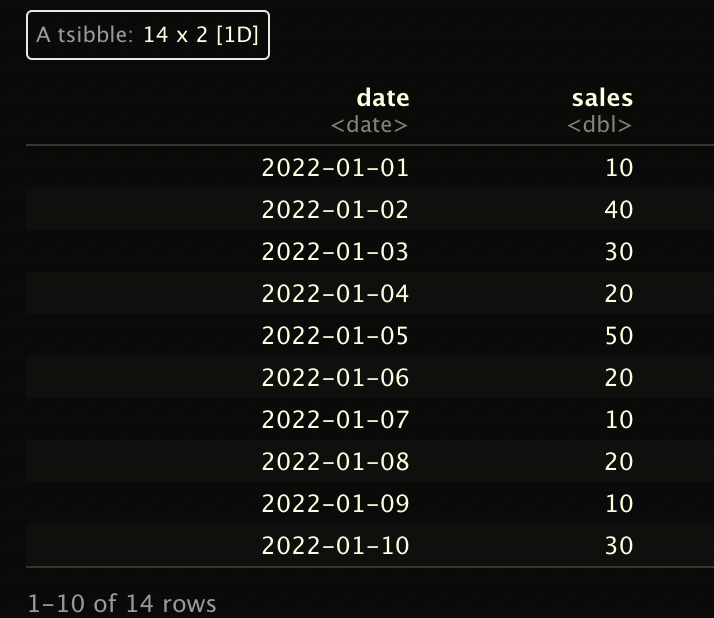
Here is my data frame.
structure(list(date = structure(c(18993, 18994, 18995, 18996,
18997, 18998, 18999, 19000, 19001, 19002, 19003, 19004, 19005,
19006), class = "Date"), sales = c(10, 40, 30, 20, 50, 20, 10,
20, 10, 30, 60, 10, 10, 50)), class = c("tbl_ts", "tbl_df", "tbl",
"data.frame"), row.names = c(NA, -14L), key = structure(list(
.rows = structure(list(1:14), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -1L)), index = structure("date", ordered = TRUE), index2 = "date", interval = structure(list(
year = 0, quarter = 0, month = 0, week = 0, day = 1, hour = 0,
minute = 0, second = 0, millisecond = 0, microsecond = 0,
nanosecond = 0, unit = 0), .regular = TRUE, class = c("interval",
"vctrs_rcrd", "vctrs_vctr")))
I'm looking for this output:
structure(list(date = structure(c(18993, 18994, 18995, 18996,
18997, 18998, 18999, 19000, 19001, 19002, 19003, 19004, 19005,
19006), class = "Date"), sales = c(10, 40, 30, 20, 50, 20, 10,
20, 10, 30, 60, 10, 10, 50), average_total_sales_at_date = c(10,
25, 26.66667, 25, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA)), row.names = c(NA,
-14L), key = structure(list(.rows = structure(list(1:14), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -1L)), index = structure("date", ordered = TRUE), index2 = "date", interval = structure(list(
year = 0, quarter = 0, month = 0, week = 0, day = 1, hour = 0,
minute = 0, second = 0, millisecond = 0, microsecond = 0,
nanosecond = 0, unit = 0), .regular = TRUE, class = c("interval",
"vctrs_rcrd", "vctrs_vctr")), class = c("tbl_ts", "tbl_df", "tbl",
"data.frame"))
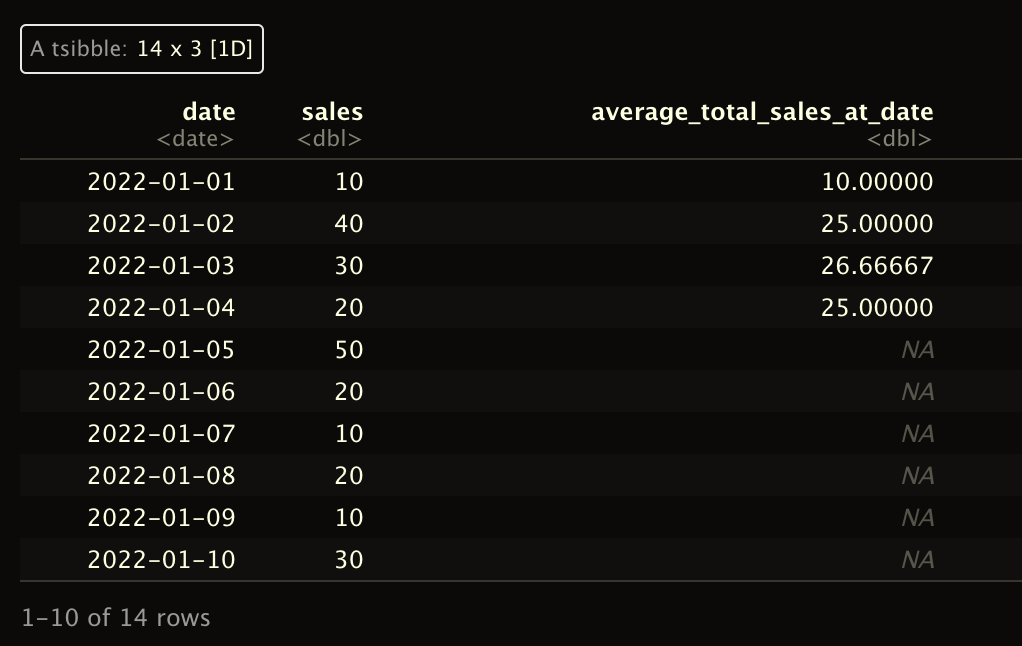
I didn't fill the numbers all the way down, but hopefully this shows the idea. I'm trying to get the total average for sales at the current date, and each new date takes an additional one day of data in calculating the total average.
CodePudding user response:
use cummean in dplyr
data%>%mutate(cummulative_average_sales=cummean(sales))
# A tibble: 14 x 3
date sales cummulative_average_sales
<date> <dbl> <dbl>
1 2022-01-01 10 10
2 2022-01-02 40 25
3 2022-01-03 30 26.7
4 2022-01-04 20 25
5 2022-01-05 50 30
6 2022-01-06 20 28.3
7 2022-01-07 10 25.7
8 2022-01-08 20 25
9 2022-01-09 10 23.3
10 2022-01-10 30 24
11 2022-01-11 60 27.3
12 2022-01-12 10 25.8
13 2022-01-13 10 24.6
14 2022-01-14 50 26.4
CodePudding user response:
library(tidyverse)
df$avg_tot_sales<-cummean(df$sales)