from selenium import webdriver
import time
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import pandas as pd
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
import requests
from csv import writer
options = webdriver.ChromeOptions()
options.add_argument("--no-sandbox")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1920x1080")
options.add_argument("--disable-extensions")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
wait = WebDriverWait(driver, 20)
URL = 'https://mergr.com/firms/search/employees?page=1&firm[activeInvestor]=2&sortColumn=employee_weight&sortDirection=asc'
driver.get(URL)
email=driver.find_element(By.CSS_SELECTOR,"input#username")
email.send_keys("[email protected]")
password=driver.find_element(By.CSS_SELECTOR,"input#password")
password.send_keys("Cosmos1990$$$$$$$")
login=driver.find_element(By.CSS_SELECTOR,"button.btn").click()
urls=[]
product=[]
soup = BeautifulSoup(driver.page_source,"lxml")
details=soup.select("tbody tr")
for detail in details:
try:
t1 =detail.select_one("h5.profile-title a").text
except:
pass
wev={
'Name':t1,
}
product.append(wev)
page_links =driver.find_elements(By.CSS_SELECTOR, "h5.profile-title p a")
for link in page_links:
href=link.get_attribute("href")
urls.append(href)
for url in urls:
driver.get(url)
soup = BeautifulSoup(driver.page_source,"lxml")
try:
website=soup.select_one("p.adress-info a[target='_blank']").text
except:
website=''
data={
'website':website
}
product.append(data)
df=pd.DataFrame(product)
df.to_csv('firm.csv')
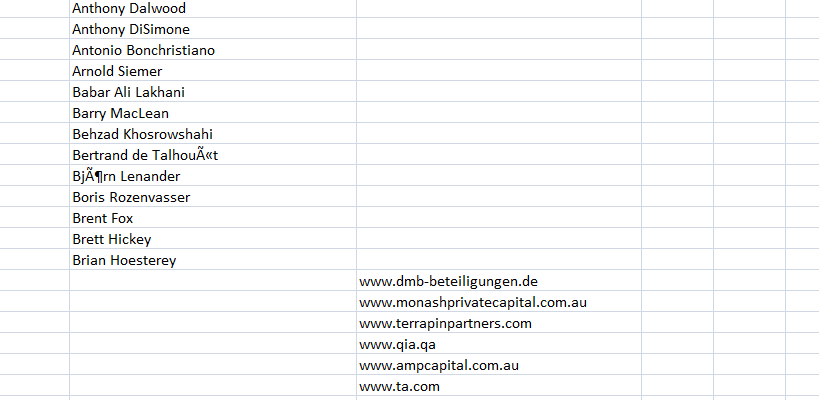
The data of the website will be down in to CSV file as shown in pic is I am appending the data in wrong way why is data moving down where I am wrong ...Kindly recommend where I am wrong there .......
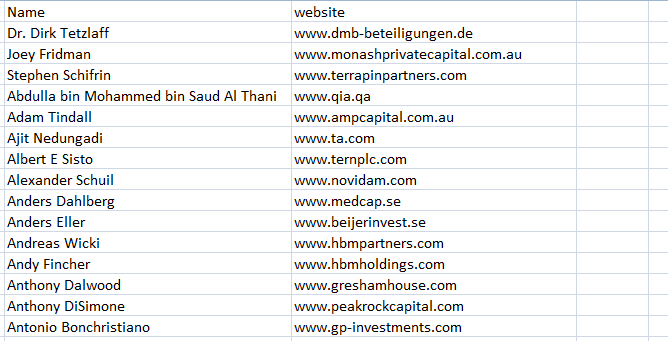
I want output in these format Kindly suggest solution for these...I want output in these format as you shown below...
CodePudding user response:
You can't append wev and data separately - you need website and name in the same dictionary for pandas to know that they belong to same row.
You could add the websites in a separate list like
sites = []
# for url in urls:
# driver.get...
# soup = ....
# try:....except:....
data={
'website':website
}
sites.append(data)
for pi, dictPair in enumerate(zip(product, sites)):
product[pi].update(dictPair[1])
df = pd.DataFrame(product)
df.to_csv('firm.csv')
However, I don't think it's the best way to make sure the right Names and Websites are matched up.
You should just add to the same dictionary for each row from the start instead of zipping and merging.
added_urls = []
product = []
soup = BeautifulSoup(driver.page_source,"lxml")
details = soup.select("tbody tr")
for detail in details:
try:
t1 = detail.select_one("h5.profile-title a").text
except:
# pass # then you'll just be using the previous row's t1
# [also, if this happens in the first loop, it will raise an error]
t1 = 'MISSING' # '' #
wev = {
'Name':t1,
}
href = detail.select_one("h5.profile-title p a[href]")
if href and href.get("href", '').startswith('http'):
wev['page_link'] = href.get("href")
added_urls.append(href.get("href"))
product.append(wev)
### IF YOU WANT ROWS THAT CAN'T BE CONNECTED TO NAMES ###
page_links = driver.find_elements(By.CSS_SELECTOR, "h5.profile-title p a")
for link in page_links:
if href in added_urls: continue # skip links that are already added
href = link.get_attribute("href")
# urls.append(href)
added_urls.append(href)
product.append({"page_link": href})
##########################################################
for pi, prod in enumerate(product):
if "page_link" not in prod or not prod["page_link"]: continue ## missing link
url = prod["page_link"]
driver.get(url)
soup = BeautifulSoup(driver.page_source,"lxml")
try:
website=soup.select_one("p.adress-info a[target='_blank']").text
except:
website=''
del product[pi]["page_link"] ## REMOVE this line IF you want a page_link column in csv
# data={'website':website}
# product.append(data)
product[pi]['website'] = website
df=pd.DataFrame(product)
df.to_csv('firm.csv')