I have data in excel file in the following format
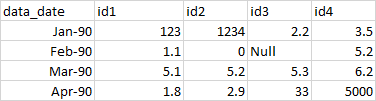
I want it to be transposed into the following format
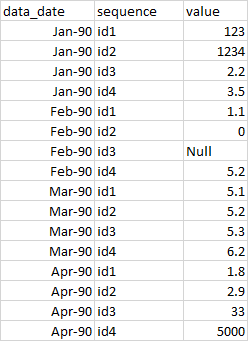
I have tried transposing the data using the following
pdf = df.toPandas()
df_transposed = pdf.T
But that didn't work and i get incorrect results... Any help please.. thanks
CodePudding user response:
For pandas , pd.melt
import pandas as pd
df = pd.DataFrame({
'category': [1,2,3,4,5],
'id1': [5,4,3,3,4],
'id2': [3,2,4,3,10],
'id3': [3, 2, 1, 1, 1]
})
category id1 id2 id3
0 1 5 3 3
1 2 4 2 2
2 3 3 4 1
3 4 3 3 1
4 5 4 10 1
pd.melt(df,id_vars=['category'], value_vars=['id1','id2','id3'],var_name='sequence', value_name='value')
For pyspark, construct a struct column of column names and their values and explode
df=spark.createDataFrame(df)
df.withColumn('tab', F.array(*[F.struct(lit(x).alias('sequence'), col(x).alias('value')).alias(x) for x in df.columns if x!='category'])).selectExpr('category','inline(tab)').show()
category sequence value
0 1 id1 5
1 2 id1 4
2 3 id1 3
3 4 id1 3
4 5 id1 4
5 1 id2 3
6 2 id2 2
7 3 id2 4
8 4 id2 3
9 5 id2 10
10 1 id3 3
11 2 id3 2
12 3 id3 1
13 4 id3 1
14 5 id3 1