I'm looking for a PostgreSQL equivalent of the image below. I have a script to batch insert multiple tables, the idea is to declare some variables to count how many of each have been inserted when executing.
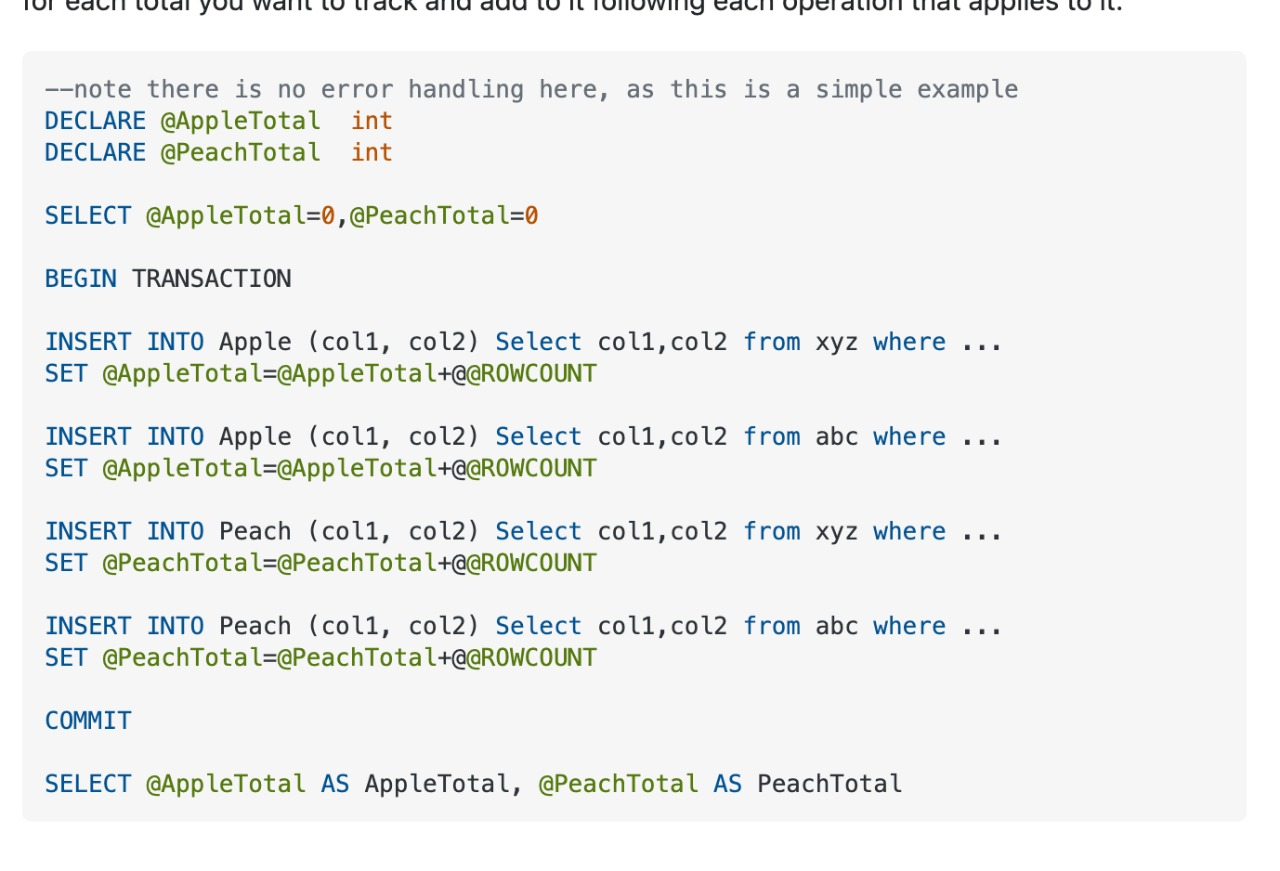
So far I have this, however there's no straightforward way for @@ROW_COUNT:
BEGIN TRANSACTION;
DO $$
DECLARE
EmailModulesTotal integer := 0;
DependenciesTotal integer := 0;
ModuleTypesTotal integer := 0;
ModuleSectionsTotal integer := 0;
BEGIN
-- inserts go here
RAISE NOTICE 'Total Inserted/Updated Email Modules: %
Total Inserted Dependencies: %
Total Inserted Module Types: %
Total Inserted Module Sections: %',
EmailModulesTotal,
DependenciesTotal,
ModuleTypesTotal,
ModuleSectionsTotal
END $$;
COMMIT TRANSACTION;
CodePudding user response:
In PL/pgSQL you can access the number of affected (i.e. inserted in your case) rows using get diagnostics. Here is an illustration.
create temporary table t (id serial, txt text);
do language plpgsql
$$
declare
counter integer;
begin
insert into t(txt) values ('One'), ('Two'), ('Three');
get diagnostics counter = row_count;
raise notice 'Inserted % rows', counter;
end;
$$;
The result is Inserted 3 rows
Another way in plain SQL is to use a data modifying CTE:
with cte as
(
insert into t(txt) values ('One'), ('Two'), ('Three')
returning 1
)
select count(*) from cte;
Whichever suits you better.