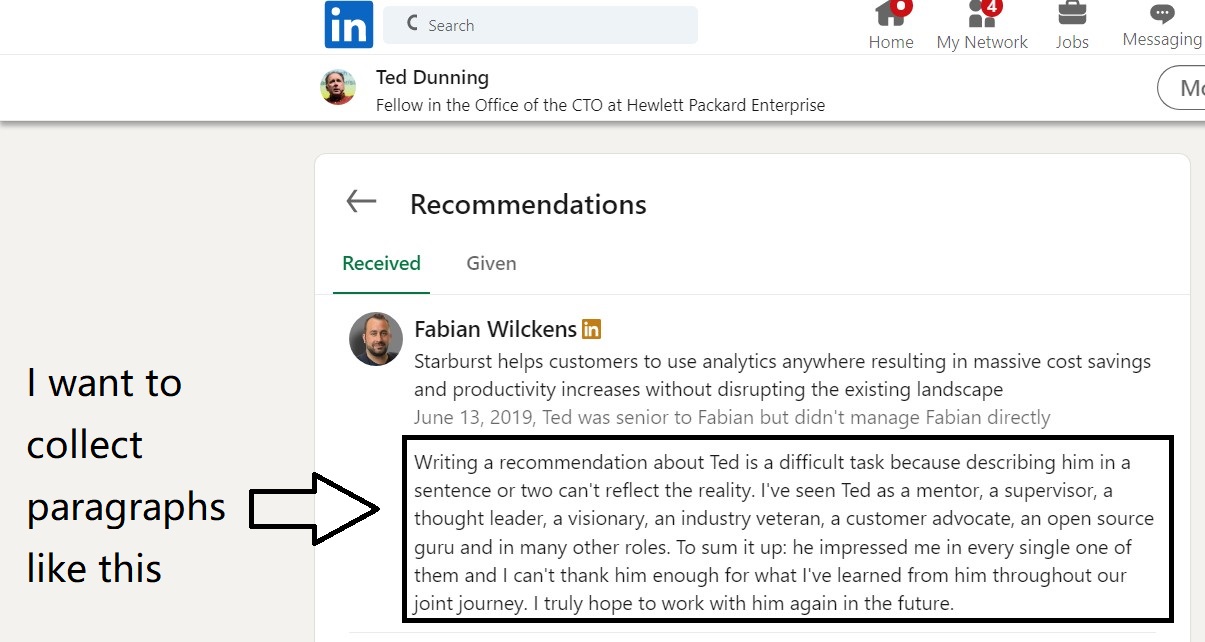
I want to collect the detailed recommendation description paragraphs that a person received on his/her LinkedIn profile, such as this link:
CodePudding user response:
Well you would first get the direct parent of the paragraphs. You can do that with XPath, class or id whatever fits best. After that you can do Your_Parent.find_elements(by=By.XPATH, value='./child::*') you can then loop over the result of that to get all paragraphs.
Edit
This selects all the paragraphs i have not yet looked into seperating them by post but here is what i got so far:
parents_of_paragraphs = driver.find_elements(By.CSS_SELECTOR, "div.display-flex.align-items-center.t-14.t-normal.t-black")
text_total = ""
for element in parents_of_paragraphs:
paragraph = element.find_element(by=By.XPATH, value='./child::*')
text_total = f"{paragraph.text}\n"
print(text_total)