I want to match every word in a large corpus against multiple different regexes. Here was my first attempt. Here, word_list is the list of all english words (I am running only against the first 1000 words in these tests):
%%time
mapping = {f'{k1}{k2}':[] for k1 in string.ascii_lowercase for k2 in string.ascii_lowercase}
for word in word_list[:1000]:
for let1,let2 in mapping:
if re.search(rf'.*{let1}.*{let2}.*', word):
mapping[let1 let2].append(word)
With an output of Wall time: 22.2 s.
Next I enveloping everything into a comprehension, such as so:
%%time
mapping = {f'{k1}{k2}':
[word for word in word_list[:1000] if re.search(rf'.*{k1}.*{k2}.*', word)]
for k1,k2 in itertools.product(string.ascii_lowercase, string.ascii_lowercase)}
With an improved time: Wall time: 608 ms.
My question is, is there any way to go even faster? Is there a way to search efficiently across an entire list, rather than going one word at a time? Any input is appreciated, really want to optimize this guy as much as possible.
To reproduce the code above, please add this code:
import nltk
nltk.download('words')
from nltk.corpus import words
word_list = words.words()
CodePudding user response:
This seems ~100 times faster than your faster way:
mapping = {f'{k1}{k2}':[] for k1 in string.ascii_lowercase for k2 in string.ascii_lowercase}
for word in word_list[:1000]:
chars = (c for c in word if c in string.ascii_lowercase)
for c1, c2 in set(itertools.combinations(chars, 2)):
mapping[c1 c2].append(word)
CodePudding user response:
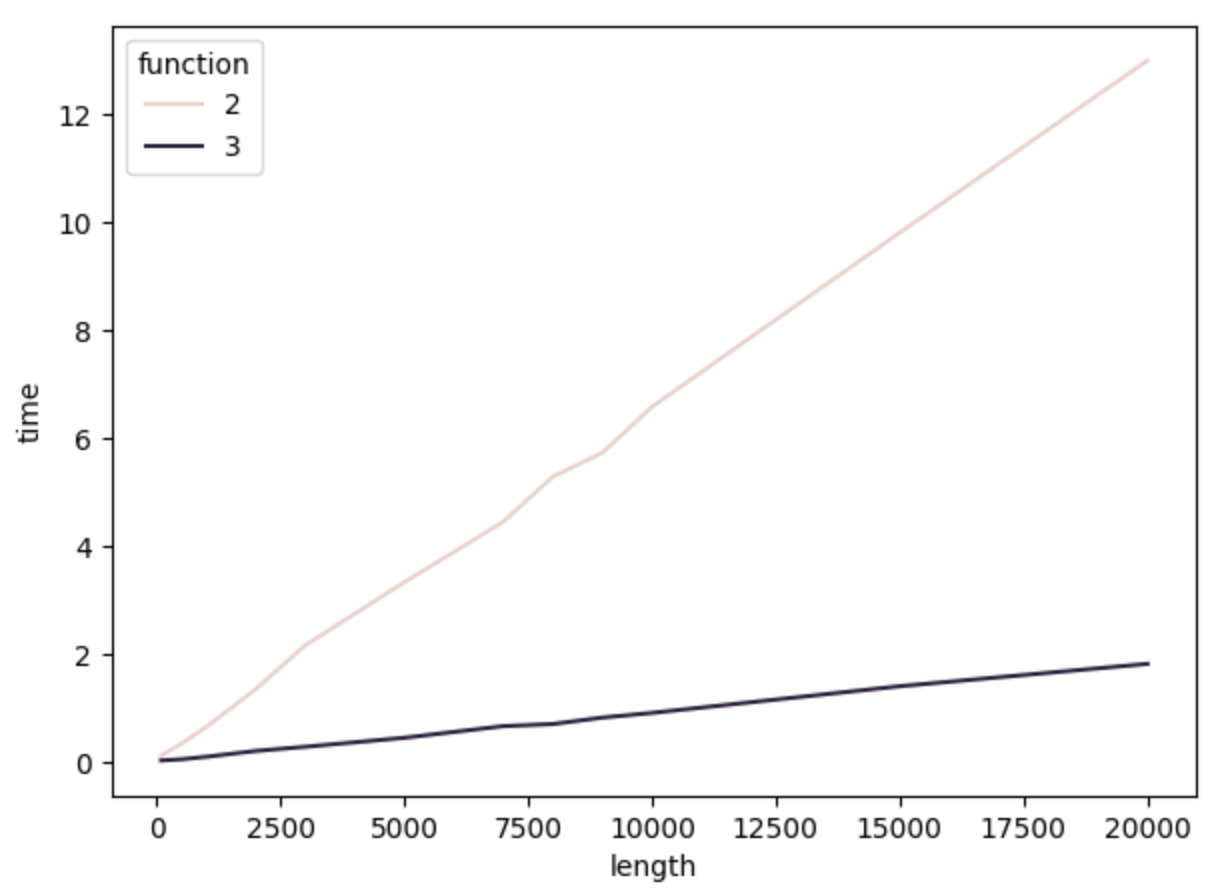
It seems sqlite3 scales much better.
# Implementation in the question
import re
import itertools
def func2(words):
mapping = {f'{k1}{k2}':
[word for word in words if re.search(rf'.*{k1}.*{k2}.*', word)]
for k1,k2 in itertools.product(string.ascii_lowercase, string.ascii_lowercase)}
return mapping
# Implementation using sqlite3
import sqlite3
def func3(words):
with sqlite3.connect("test2.db") as conn:
c = conn.cursor()
c.execute("DROP TABLE IF EXISTS words")
c.execute("CREATE TABLE words (word TEXT)")
c.executemany("INSERT INTO words VALUES (?)", [(w,) for w in words])
c.execute("DROP TABLE IF EXISTS keywords")
c.execute("CREATE TABLE keywords (keyword TEXT, key TEXT)")
values = [(f"*{k1}*{k1}*", f"{k1}{k2}") for k1 in string.ascii_lowercase for k2 in string.ascii_lowercase]
c.executemany("INSERT INTO keywords VALUES (?,?)", values)
conn.create_function("matched", 2, matched, deterministic=True)
c = conn.cursor()
c.execute("""
SELECT
k.key, w.word
FROM
words AS w
INNER JOIN keywords AS k ON w.word GLOB k.keyword
""")
mapping = {f'{k1}{k2}':[] for k1 in string.ascii_lowercase for k2 in string.ascii_lowercase}
for key, word in c:
mapping[key].append(word)
return mapping
Here is a comparison
from datetime import datetime
import pandas as pd
out = []
for i in [100, 500, 1000, 2000, 3000, 5000, 7000, 8000, 9000, 10000, 15000, 20000]:
print(f"Now at {i}")
for j, func in zip([2,3], [func2, func3]):
t1 = datetime.now()
func(word_list[:i])
t2 = datetime.now()
out.append([i, j, (t2-t1).total_seconds()])
out = pd.DataFrame(out, columns=["length", "function", "time"])
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots(figsize=(7, 5))
sns.lineplot(data=out, x="length", y="time", hue="function", ax=ax)