I have a dataframe like as below
df = pd.DataFrame(
{'stud_id' : [101, 101, 101, 101,
101, 102, 102, 102],
'sub_code' : ['CSE01', 'CSE01', 'CSE01',
'CSE01', 'CSE02', 'CSE02',
'CSE02', 'CSE02'],
'ques_date' : ['10/11/2022', '06/06/2022','09/04/2022', '27/03/2022',
'13/05/2010', '10/11/2021','11/1/2022', '27/02/2022'],
'revenue' : [77, 86, 55, 90,
65, 90, 80, 67]}
)
df['ques_date'] = pd.to_datetime(df['ques_date'])
I would like to do the below
a) Compute custom financial year based on our organization FY calendar. Meaning, Oct-Dec is Q1, Jan -Mar is Q2,Apr - Jun is Q3 and July to Sep is Q4.
b) Group by stud_id
c) Compute sum of revenue from previous two custom FYs (from a specific date = 20/12/2022). For example, if we are in the FY-2023, I would like to get the sum of revenue for a customer from FY-2022 and FY-2021 separately
So, I tried the below based on this post 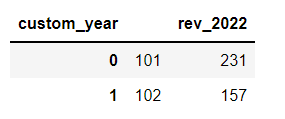
I expect my output to be like as below
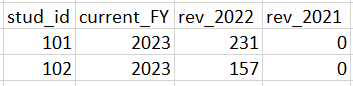
updated output
CodePudding user response:
It seems you just need to first fine the quarter year, filter to only include 2021 and 2022 rows, and then summarize & pivot:
(df.assign(
qyear = pd.to_datetime(df['ques_date'], dayfirst=True).dt.to_period('Q-SEP').dt.qyear
)[lambda x: x.qyear.isin([2021, 2022])]
.assign(qyear=lambda x: x.qyear.astype('category').cat.set_categories([2021, 2022]))
.groupby(['stud_id', 'qyear'])
.revenue.sum()
.unstack(level=1)
.add_prefix('rev_')
.reset_index(drop=False))
#qyear stud_id rev_2021 rev_2022
#0 101 0 231
#1 102 0 157
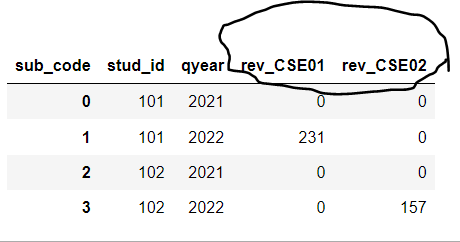
For the update:
df['qyear'] = pd.to_datetime(df['ques_date'], dayfirst=True).dt.to_period('Q-SEP').dt.qyear.astype('category').cat.set_categories([2021, 2022])
df.groupby(['stud_id', 'sub_code', 'qyear']).revenue.sum().unstack(level=1, fill_value=0).add_prefix('rev_').reset_index(drop=False)
sub_code stud_id qyear rev_CSE01 rev_CSE02
0 101 2021 0 0
1 101 2022 231 0
2 102 2021 0 0
3 102 2022 0 157