In dataset, I have two columns
- N: ID number to identify each row
- Indicator: it is either 0 or 1.
What I would like to obtain:
- Cumsum: calculate the cumulative cum of the column Indicator, but only to successive values of 1.
- Total: then for each chunk of non-null values, get the total of non-null values (or the max of the cum sum, or the last value) for each chunk
How can I get the two columns efficiently?
(A for loop over the rows would not be efficient.)
CodePudding user response:
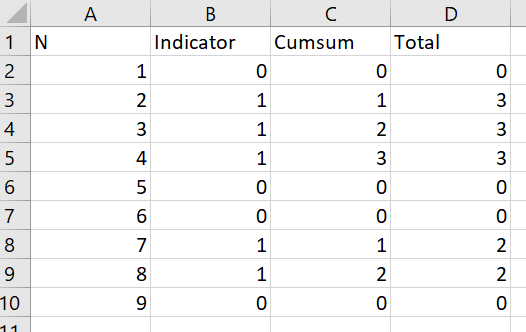
Example
we need code of example for answer
df = pd.DataFrame([0, 0, 1, 1, 1, 0, 0, 1, 1], columns=['Ind'])
df
Ind
0 0
1 0
2 1
3 1
4 1
5 0
6 0
7 1
8 1
Code
g = df['Ind'].ne(df['Ind'].shift()).cumsum()
df['Cumsum'] = df.groupby(g).cumsum()
df['Total'] = df.groupby(g)['Cumsum'].transform(max)
df
Ind Cumsum Total
0 0 0.0 0.0
1 0 0.0 0.0
2 1 1.0 3.0
3 1 2.0 3.0
4 1 3.0 3.0
5 0 0.0 0.0
6 0 0.0 0.0
7 1 1.0 2.0
8 1 2.0 2.0
CodePudding user response:
Something with the same logic
s = df['indicator'].eq(0).cumsum()
df['new1'] = df.groupby(s).cumcount()
df['new2'] = df.groupby(s)['indicator'].transform('sum')*df['indicator']
df
Out[458]:
indicator new1 new2
0 0 0 0
1 0 0 0
2 1 1 3
3 1 2 3
4 1 3 3
5 0 0 0
6 0 0 0
7 1 1 2
8 1 2 2