I'm beginner in python, I have two dataframes as below. The first dataframe represents the user with their vectors and group number.
df1 = pd.DataFrame({'user': ['user 1', 'user 2', 'user 3', 'user 4', 'user 5'], 'x1': [[0.2, 0.3, 0.5],[0.3, 0.3, 0.4],[0.4, 0.4, 0.2],[0.2, 0.1, 0.7],[0.5,0.3,0.2]],'group': [1, 0, 0, 2, 1]})
df1
output:
user x1 group
0 user 1 [0.2, 0.3, 0.5] 1
1 user 2 [0.3, 0.3, 0.4] 0
2 user 3 [0.4, 0.4, 0.2] 0
3 user 4 [0.2, 0.1, 0.7] 2
4 user 5 [0.5, 0.3, 0.2] 1
the second dataframe represents the group number with its vector and variable (p2) and its threshold
df2 = pd.DataFrame({'group': [0, 1, 2],
'x2': [[0.4, 0.2, 0.4],[0.5, 0.1, 0.4], [0.5, 0.1, 0.4]],
'p2': [0.231, 0.342, 0.411],
'threshold': [0.9, 0.6, 0.8]})
df2
output:
group x2 p2 threshold
0 0 [0.4, 0.2, 0.4] 0.231 0.9
1 1 [0.5, 0.1, 0.4] 0.342 0.6
2 2 [0.5, 0.1, 0.4] 0.411 0.8
I am trying to calculate for each user, the score (S) with respect to the group it was assigned by using:
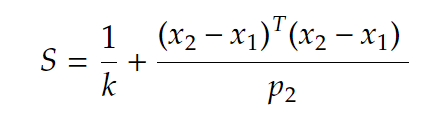
where k= group size and T is the transport matrix of (x2 -x1).
Then check:
1- If the score is below the threshold of its group, the user does not change its group.
2- If the score is higher than the threshold then we calculate the score for the other groups and will assign the user to the group for each the score is below the threshold. In case this is true for more than one group we will assign the user to the group for which the score is lowest.
3- If the score is above the threshold for all the groups then this user will give the start of a new group.
For example, for user 1 that belongs to group 1.
x2 =(0.5, 0.1, 0.4)
x1 =(0.2, 0.3, 0.5)
So x2 -x1= (0.3, -0.2, -0.1)
then transport of this vector is
(0.3,
-0.2,
-0.1)
so multiplying the transport of this vector by (x2 -x1) is equal to:
(0.9 0.4 0.1)= 0.14
K= 2
p2 of its cluster=0.342
The score (S) for user 1:
= 1/2 (0.14/0.342)= 0.5 ( 0.4093)= 0.90
We can see that score of user 1 is higher than its group threshold (0.6) So, we need to calculate the score for the other groups (0 and 2) and will assign the user to the group for each score below the threshold. How could I do that for all users?
CodePudding user response:
First, count up the members of each group to get the k term:
df2['count'] = df1.groupby('group')['user'].count()
Then merge df1 and df2 so that we have a frame with all necessary parameters for each user in a single row:
joined = df1.join(df2[['x2', 'p2', 'threshold', 'count']], on='group')
print(joined)
>>> user x1 group x2 p2 threshold count
0 user 1 [0.2, 0.3, 0.5] 1 [0.5, 0.1, 0.4] 0.342 0.6 2
1 user 2 [0.3, 0.3, 0.4] 0 [0.4, 0.2, 0.4] 0.231 0.9 2
2 user 3 [0.4, 0.4, 0.2] 0 [0.4, 0.2, 0.4] 0.231 0.9 2
3 user 4 [0.2, 0.1, 0.7] 2 [0.5, 0.1, 0.4] 0.411 0.8 1
4 user 5 [0.5, 0.3, 0.2] 1 [0.5, 0.1, 0.4] 0.342 0.6 2
Now define functions to calculate the S score:
def l_delta(z1, z2):
return [a1 - a2 for (a1, a2) in zip(z1, z2)]
def inner(z1, z2):
return sum([a1 * a2 for (a1, a2) in zip(z1, z2)])
def s_score(row):
delta = l_delta(row['x2'], row['x1'])
num = inner(delta, delta)
return 1/row['count'] num / row['p2']
Finally, apply these functions to each row in the joined matrix:
joined['s_score'] = joined.apply(s_score, axis=1)
print(joined[['user', 's_score']])
Result:
user s_score
0 user 1 0.909357
1 user 2 0.586580
2 user 3 0.846320
3 user 4 1.437956
4 user 5 0.733918
CodePudding user response:
Similar answer to @The Photon, where we (1) merge df1 and df2, (2) calculate k with groupby (3) calculate (x2-x1) inner product with itself
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'user': ['user 1', 'user 2', 'user 3', 'user 4', 'user 5'],
'x1': [[0.2, 0.3, 0.5],[0.3, 0.3, 0.4],[0.4, 0.4, 0.2],[0.2, 0.1, 0.7],[0.5,0.3,0.2]],
'group': [1, 0, 0, 2, 1]})
df2 = pd.DataFrame({'group': [0, 1, 2],
'x2': [[0.4, 0.2, 0.4],[0.5, 0.1, 0.4], [0.5, 0.1, 0.4]],
'p2': [0.231, 0.342, 0.411],
'threshold': [0.9, 0.6, 0.8]})
#merge df1 and df2 into a single table
merged_df = df1.merge(df2)
#calculate the number of unique users per group (k)
merged_df['k'] = merged_df.groupby('group')['user'].transform('nunique')
#calculate x2-x1 for each user (convert to numpy array for vectorized subtraction)
x2_sub_x1 = merged_df['x2'].apply(np.array)-merged_df['x1'].apply(np.array)
#calculate (x2-x1)T(x2-x1) for each user (same as squaring each term and summing)
numerator = x2_sub_x1.pow(2).apply(sum)
#calculate S from your formula and add it as a column to the merged table
merged_df['S'] = (1/merged_df['k']) (numerator/merged_df['p2'])
Final merged table
user x1 group x2 p2 threshold k S
0 user 1 [0.2, 0.3, 0.5] 1 [0.5, 0.1, 0.4] 0.342 0.6 2 0.909357
1 user 5 [0.5, 0.3, 0.2] 1 [0.5, 0.1, 0.4] 0.342 0.6 2 0.733918
2 user 2 [0.3, 0.3, 0.4] 0 [0.4, 0.2, 0.4] 0.231 0.9 2 0.586580
3 user 3 [0.4, 0.4, 0.2] 0 [0.4, 0.2, 0.4] 0.231 0.9 2 0.846320
4 user 4 [0.2, 0.1, 0.7] 2 [0.5, 0.1, 0.4] 0.411 0.8 1 1.437956