There are several articles and converting timestamps in R, but I cannot see to find any solution to this problem. I am trying to extract an environmental dataset within a CSV file, I would like to understanding what is the max CO2 value only working days and between 0800 to 1700. The CSV has the following format:
timestamp,co2,humid,light,noise,pm25,score,temp(°C),voc
2022-10-03 23:15:00,899.0,55.2,349.2,51.3,22.0,80.0,22.9,646.0
2022-10-03 23:20:00,903.2,55.2,329.0,50.7,21.3,81.4,22.9,460.5
2022-10-03 23:25:00,910.8,54.8,347.6,51.6,21.6,81.1,23.1,513.4
2022-10-03 23:30:00,917.4,54.4,430.9,53.7,21.7,80.7,23.3,571.4
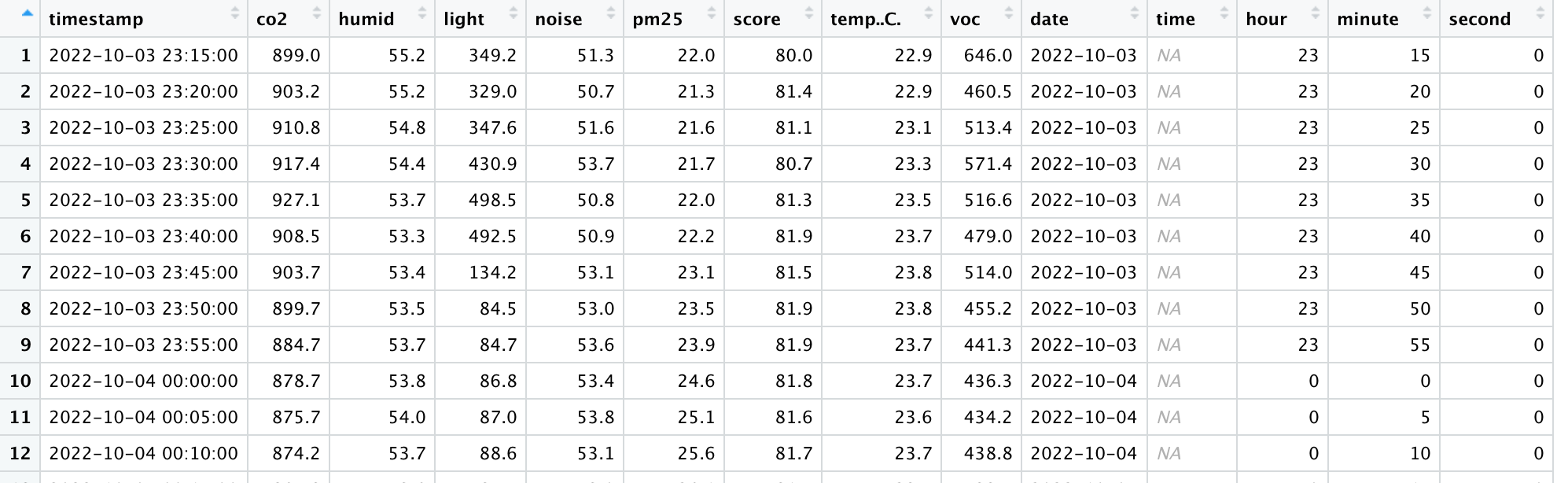
The code loads the CSV and can view the DF the date extract works okay, but the time extract just provides n/a. I have tried different solutions, I can extract the hours, minutes, seconds and these are contained in the DF (see the screenshot).
What I cannot work out if there is the ability to extract the time from the timestamp or if I need to rejoin the individual hours, minutes, seconds for the comparison to work. The problem is I cannot get the time format correct as it's needs to be in a format HH:MM:SS.
library(lubridate)
library(dplyr)
# read in CSV file, limited to the first 50 rows
df <- read.csv("data.csv",nrows=50)
# convert "date" column to a date object
df$timestamp <- ymd_hms(df$timestamp)
View(df$timestamp)
# Extract the date
df$date <- date(df$timestamp)
# Extract the time, !! but this does work and obtaining n/a
df$time <- parse_date_time(df$timestamp, '%H:%M:%S')
df$hour<- hour(df$timestamp)
df$minute<- minute(df$timestamp)
df$second<- second(df$timestamp)
df <- df %>%
filter(!is.weekend(date) & time >= hms("08:00:00") & time <= hms("17:00:00"))
df <- df %>%
group_by(date) %>%
summarize(min = min(value), max = max(value))
df
The data contained in the DF, df$time is always n/a and the hour, minute, seconds is extract but contain within individual df cells.
CodePudding user response:
You can use lubridate functions directly on timestamp without all the additional conversions.
library(dplyr)
library(lubridate)
df %>%
filter(wday(timestamp) %in% 2:6 & hour(timestamp) >= 8 & hour(timestamp) <= 17) %>%
group_by(date = as.Date(timestamp)) %>%
summarize(min = min(co2), max = max(co2))
(With your example data, this results in an empty dataframe since all the times you provided are later than 17:00.)