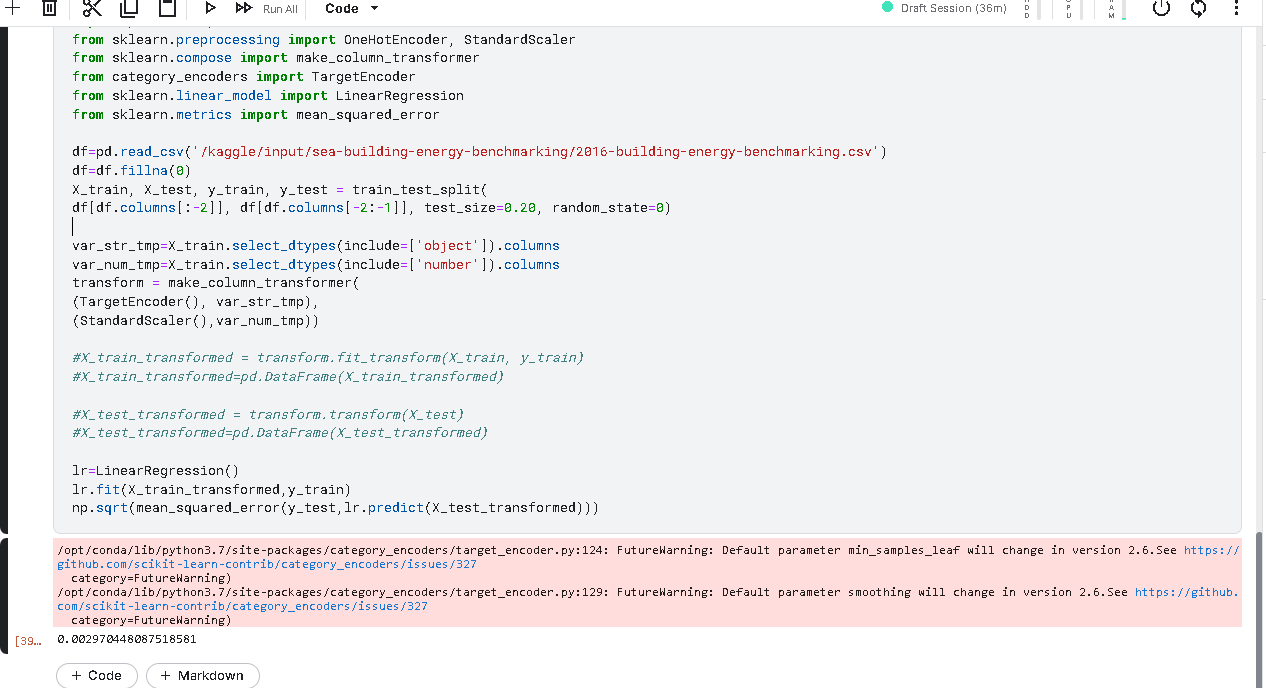
In order to train myself in machine learning, I use the dataset "2016_Building_Energy_Benchmarking.csv" which contains information on the energy expenditure and C02 emissions of several thousands of buildings in Seattle (output variables) as well as input variables which are qualitative (type of building, name of the neighbourhood) and quantitative (number of floors, electrical expenditure, surface area...) To predict my output variables (here first the total CO2 emissions), I decided to operate on about ten variables by encoding my qualitative variables and then using a StandardScaler:
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import make_column_transformer
from seaborn import load_dataset
import pandas as pd
from category_encoders import TargetEncoder
transform = make_column_transformer(
(TargetEncoder(), var_str_tmp),
(StandardScaler(),var_num_tmp))
X_train_transformed = transform.fit_transform(X_train,y_train)
X_train_transformed=pd.DataFrame(X_train_transformed)
X_test_transformed = transform.transform(X_test)
X_test_transformed=pd.DataFrame(X_test_transformed)
lr=LinearRegression()
lr.fit(X_train_transformed,y_train)
np.sqrt(metrics.mean_squared_error(y_test,lr.predict(X_test_transformed)))
0.0030159672906212576
The problem, as you can see, is that the RMSE for a linear regression is very, very low, which I think is impossible for such a problem. As this problem disappears when I remove the standardcaler (the rmse is then 500), the reason comes from there it seems but I don't know how to rectify.
I tried to change the scaler to another one, the problem is still the same.
I also tried this instead but that didn't help :
encoder=TargetEncoder() X_train_transformed=encoder.fit_transform(X_train,y_train) X_test_transformed=encoder.transform(X_test) scaler=StandardScaler() X_train_transformed=scaler.fit_transform(X_train_transformed) X_test_transformed=scaler.transform(X_test_transformed)
With the help of a LazyRegressor, I also realised that the RMSE was also equal to 0 for other models (RidgeCV, Ridge, LassoCV, Lasso, BayesianRidge...) but that it seemed normal for the other models
I would be very grateful to anyone who could solve this problem.
CodePudding user response:
I created a kaggle notebook on kaggle for this dataset. I re-ran the notebook twice...once with scaling and once without. I got the same rmse of 0.003.
There is definitely target leakage that resulted in such a small margin (I see features for amount of natural gas burned, electricity usage etc all of these are events that has already occurred). However to answer the question as to why scaling affected the result...I think it has to with errors in your code for how features are in included in the scaler or maybe the memory is not cleared when you re-ran the notebook.