I have to edit some log result in excel sheet to make it more meaningful. But the log file is very large and there are many differences. The pattern is not perfectly the same.
Because of these differences, VLOOKUP didn't work. But the only similarity is that there are rows as delimeters such as "________".
So for a better explanation, I have a data like this;
__________
A
B
C
__________
A
B
D
__________
But I want it to be like this;
A B C
A B D
.
.
.
and so on.
I know that TRANSPOSE does the convert thing. But It is so simple for me to use as I need to use this function for multiple groups within the same column.
I was going to ask if this is possible to do.
CodePudding user response:
With the sample given, try:
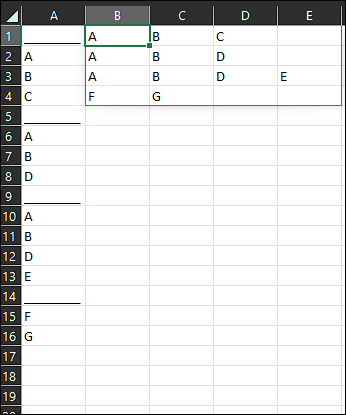
Formula in B1:
=IFERROR(DROP(REDUCE(0,TOCOL(A:A,1),LAMBDA(a,b,IF(b= "________",VSTACK(a,0),VSTACK(DROP(a,-1),HSTACK(TOROW(TAKE(a,-1),3),b))))),1,1),"")
CodePudding user response:
If you have TEXTSPLIT available, you can try the following in cell C1:
=TEXTSPLIT(TEXTJOIN("",,IF(A1:A13="________", ";",A1:A13&",")),",",";",1,,"")
here is the output:
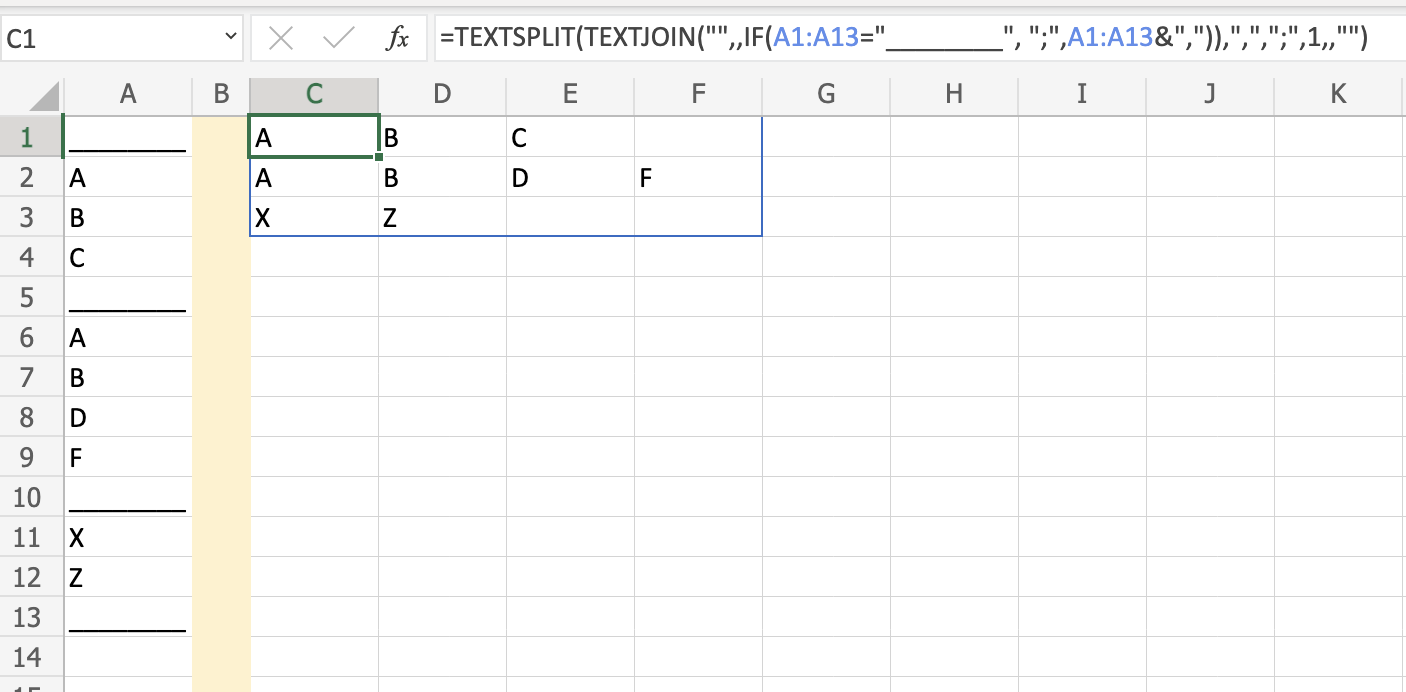
I am using as row, and column delimiter ;, , respectively, but you can customize it to a different token if such characters are present in your input data. I replaced the row separator: (_____) with ; in the IF statement just for convenience, it is not really necessary.
Another possible solution is to calculate the index position (idx) of the row delimiter (_____). Identify start and end of each subset. Use REDUCE to iterate over each segment (SEQUENCE(ROWS(start))) and via FILTER to identify the corresponding subset. Apply TOROW to transpose FILTER result and append each row added via VSTACK on each iteration. DROP is used to remove the first row related to the initial value of the accumulator (ac) and IFERROR to remove #N/A values generated by VSTACK when the number of columns is less than the maximum number of columns of the output.
Here is the approach:
=LET(rng,A1:A13,seq,SEQUENCE(ROWS(rng)),idx,FILTER(seq, ISNUMBER(FIND("_____",rng))),
start,DROP(idx 1,-1),end,DROP(idx-1,1), IFERROR(DROP(REDUCE("", SEQUENCE(ROWS(start)),
LAMBDA(ac,p,VSTACK(ac,TOROW(FILTER(rng, (seq >= INDEX(start,p)) * (seq <= INDEX(end,p)))
)))),1),""))
It is a lengthy solution but it is similar to the mental steps an algorithm should follow: 1) Find start and end, 2) Extract subset, 3) Transpose, 4) Append.