I have a data that looks like this
| tx_id | tx_date | product_id |
|---|---|---|
| 1 | 1/4/2023 | 3 |
| 1 | 1/4/2023 | 5 |
| 2 | 1/4/2023 | 3 |
| 3 | 1/4/2023 | 1 |
| 4 | 1/4/2023 | 1 |
| 4 | 1/4/2023 | 5 |
| 1 | 1/5/2023 | 5 |
| 1 | 1/5/2023 | 1 |
| 2 | 1/5/2023 | 4 |
| 2 | 1/5/2023 | 6 |
| 3 | 1/5/2023 | 1 |
Quick explanation for the columns
tx_id is a transaction id
tx_date is a transaction date
product_id is a product id
The behavior of the data here is that the tx_id being reset to 1 if the day changed
I was expecting to update the data to be like this by using pyspark / pandas
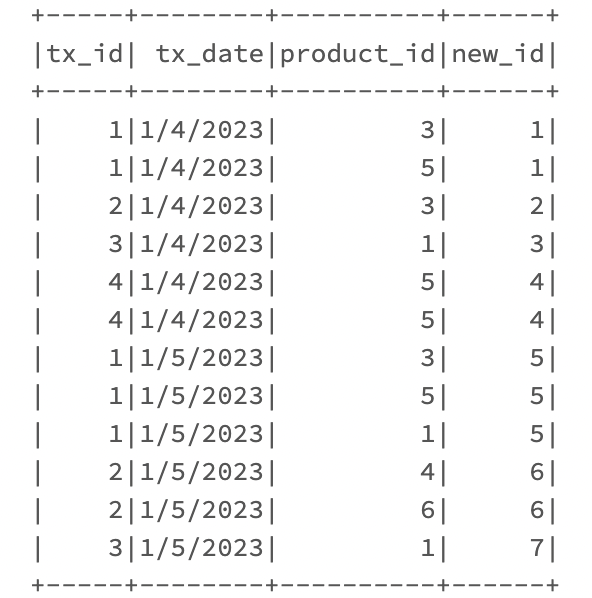
Take a quick look at the new id number 4 and 5
| id | tx_id | tx_date | product_id |
|---|---|---|---|
| 1 | 1 | 1/4/2023 | 3 |
| 1 | 1 | 1/4/2023 | 5 |
| 2 | 2 | 1/4/2023 | 3 |
| 3 | 3 | 1/4/2023 | 1 |
| 4 | 4 | 1/4/2023 | 1 |
| 4 | 4 | 1/4/2023 | 5 |
| 5 | 1 | 1/5/2023 | 5 |
| 5 | 1 | 1/5/2023 | 1 |
| 6 | 2 | 1/5/2023 | 4 |
| 6 | 2 | 1/5/2023 | 6 |
| 7 | 3 | 1/5/2023 | 1 |
A quick explanation of what I was expecting is how do I make a new id column with index based on the tx_id, tx_date, and product_id
CodePudding user response:
If uniqueness of the index is your main concern, resetting the entire dataframe index can be helpful.
df=df.reset_index(drop=True)
CodePudding user response:
This would work (in pyspark):
df.withColumn("new_id", F.dense_rank().over(Window.orderBy(col("tx_date"), col("tx_id")))).show()