I have a assignment dataset which consists of students' grades sorted by academic groups for various modules. In my assignment, I used the following code to acquire an output which I later hardcoded it into a table:
math_comparison_size = data.groupby(["Academic Group","Math.SemGrade"]).size()
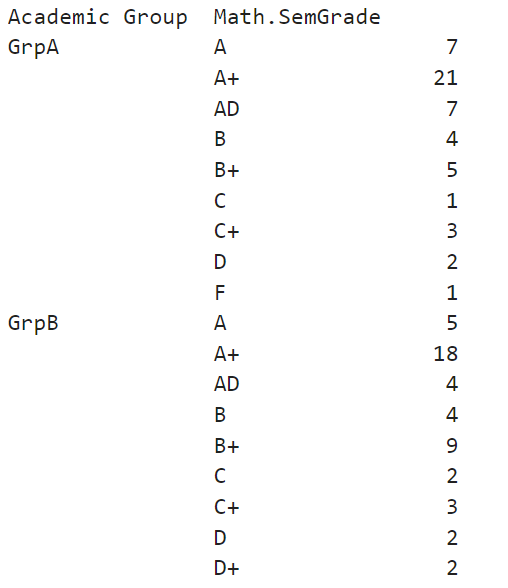
Is there a way where I can combine/merge certain rows together to increase their values?
Such as:
A (combination of A and A values for each academic group E.g. for Group A it will be 28 instead of 7 and 21)
so on and forth...
CodePudding user response:
Update
>>> df.unstack(level=0).groupby(df.index.levels[1].map(mapping)).sum()
Academic Group Grp A Grp B Grp C Grp D Grp E
Math.SemGrade
A 43 49 93 82 39
B 24 69 65 59 57
C 20 8 5 23 13
Input data:
Academic Group Math.SemGrade
Grp A A 13
A 17
AD 6
B 1
B 6
C 9
C 0
D 9
D 6
F 20
Grp B A 6
A 8
AD 19
B 6
B 10
C 24
C 5
D 11
D 29
F 8
Grp C A 22
A 27
AD 16
B 14
B 14
C 26
C 14
D 0
D 25
F 5
Grp D A 29
A 23
AD 2
B 11
B 17
C 1
C 27
D 3
D 28
F 23
Grp E A 2
A 9
AD 4
B 9
B 15
C 18
C 10
D 5
D 24
F 13
dtype: int64
Old answer
If you want to group by the first letter (A -> A, A -> A, ...), you can use:
>>> (df.groupby(df['Maths Semester Grades'].str[0])
.sum(numeric_only=True).reset_index())
Maths Semester Grades Grp A Grp B Grp C Grp D Grp E
0 A 36 33 65 54 15
1 B 7 16 28 28 24
2 C 9 29 40 28 28
3 D 15 40 25 31 29
4 F 20 8 5 23 13
If you want to control the groups, use a mapping dict:
mapping = {'A': 'A', 'A ': 'A', 'AD': 'A', 'B': 'A', 'B ': 'A',
'C': 'B', 'C ': 'B', 'D': 'B', 'D ': 'B',
'E': 'C', 'F': 'C'}
>>> (df.groupby(df['Maths Semester Grades'].map(mapping))
.sum(numeric_only=True).reset_index()
Maths Semester Grades Grp A Grp B Grp C Grp D Grp E
0 A 43 49 93 82 39
1 B 24 69 65 59 57
2 C 20 8 5 23 13
Input dataframe:
>>> df
Maths Semester Grades Grp A Grp B Grp C Grp D Grp E
0 A 13 6 22 29 2
1 A 17 8 27 23 9
2 AD 6 19 16 2 4
3 B 1 6 14 11 9
4 B 6 10 14 17 15
5 C 9 24 26 1 18
6 C 0 5 14 27 10
7 D 9 11 0 3 5
8 D 6 29 25 28 24
9 F 20 8 5 23 13
CodePudding user response:
Use DataFrame.groupby().sum() to group rows based on one or multiple columns and calculate sum agg function. groupby() function returns a DataFrameGroupBy object which contains an aggregate function sum() to calculate a sum of a given column for each group.
In this article, I will explain how to use groupby() and sum() functions together with examples. group by & sum on single & multiple columns is accomplished by multiple ways in pandas, some among them are groupby(), pivot(), transform(), and aggregate() functions. enter link description here