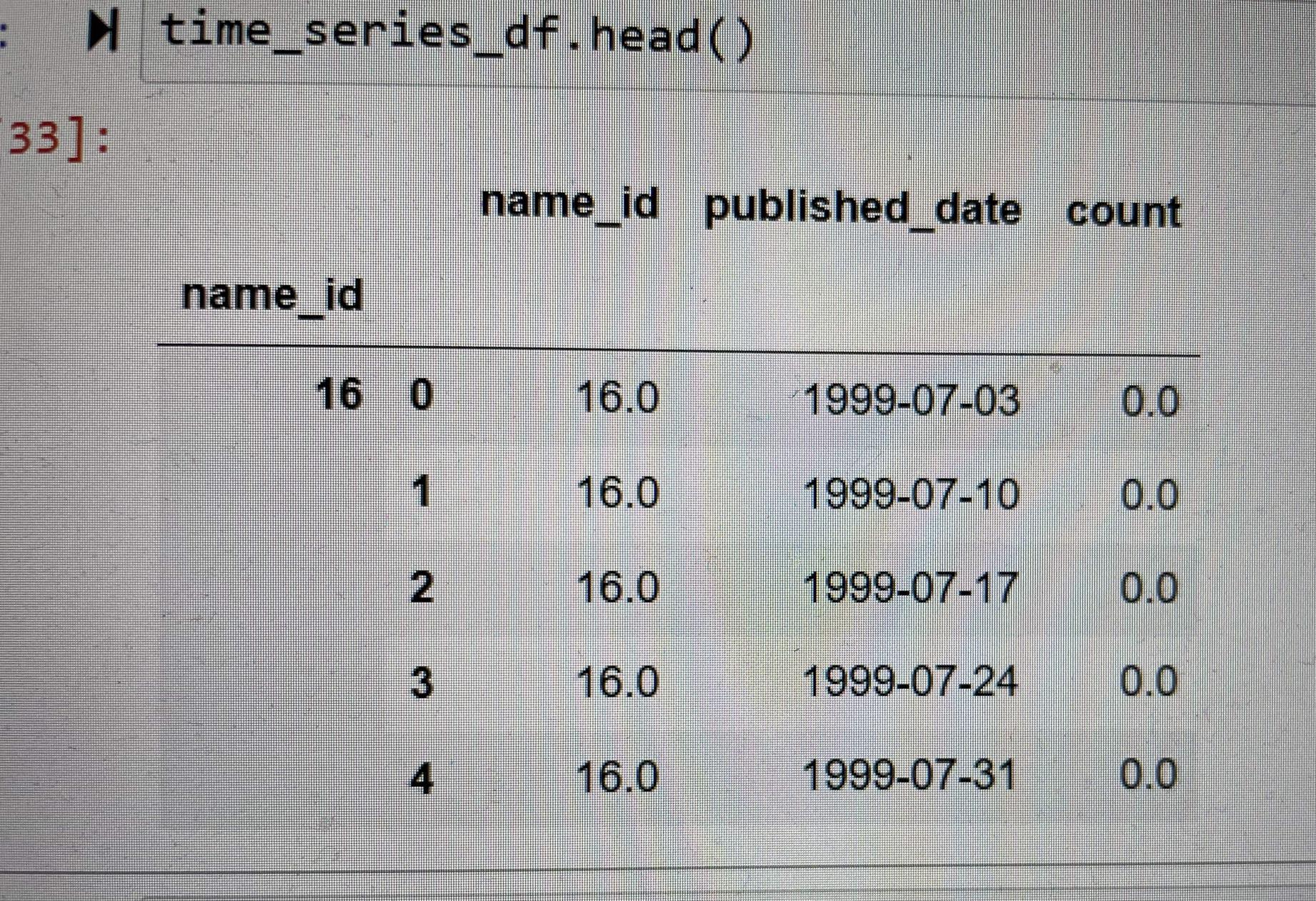
I have a merged column of "name_id" in the left as it shown below. I have used df=df.loc[:,~df.columns.duplicated()] also but did not remove it. Any ideas? thanks.
CodePudding user response:
if you want to delete the merged rows name_id
the name_id on the left has been set as index. try to reset it first:
df = df.reset_index(level=0)
then try to remove duplicates again
if you want to delete the name_id column with value in each row
df= df.drop(df.columns['name_id'], axis = 1)
CodePudding user response:
Try this:
time_series_df.droplevel(0)
You'll have a multi-index after a groupby. You can drop that column as above.