I am trying to get the min and max date from each table in a database in databricks.
I already started with the following:
results =[]
tables_list = spark.sql('show tables in table')
for row in tables_list.collect():
tablename = row.tableName
min_update = spark.sql(f"SELECT MIN(date) FROM table.{tablename}").collect()[0][0]
max_update = spark.sql(f"SELECT MAX(date) FROM table.{tablename}").collect()[0][0]
results.append((tablename,min_update,max_update))
df_update = spark.createDataFrame(results, schema = ['tablename', 'min_update', 'max_update'])
but when I df_update.display() I only get the last table where I expect to have 60 tables each with the max and min dates for each row of table.
CodePudding user response:
Since you want to get the max and min date from all the tables, you need to include the append operation inside the for loop.
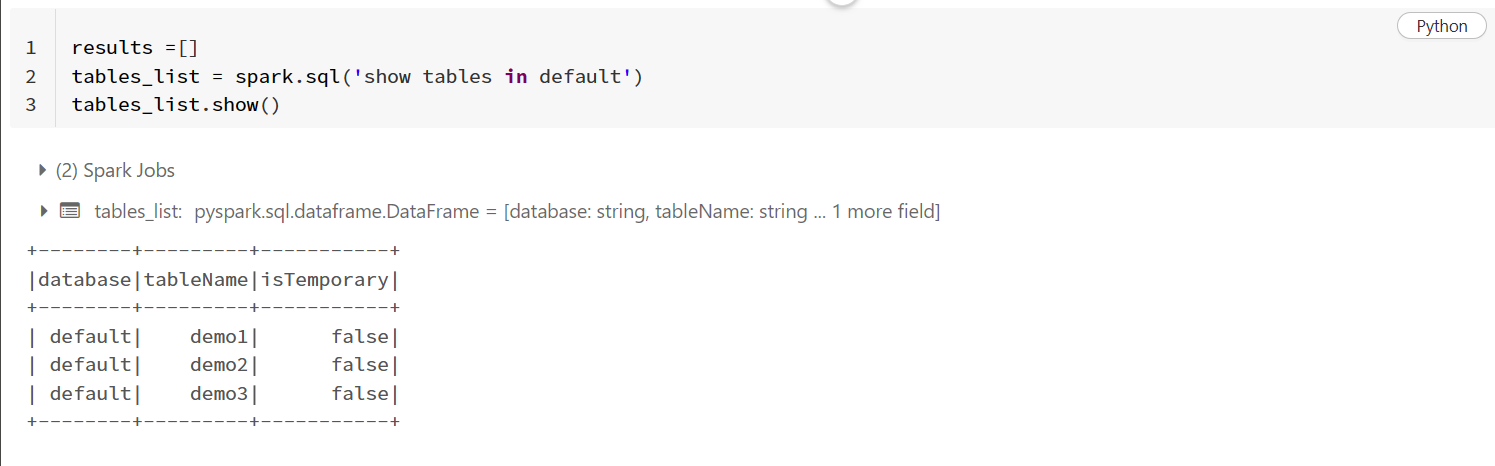
Look at the following where I have modified the same code and got the required results. The following is a dataframe after executing show tables:
results =[]
tables_list = spark.sql('show tables in default')
tables_list.show()
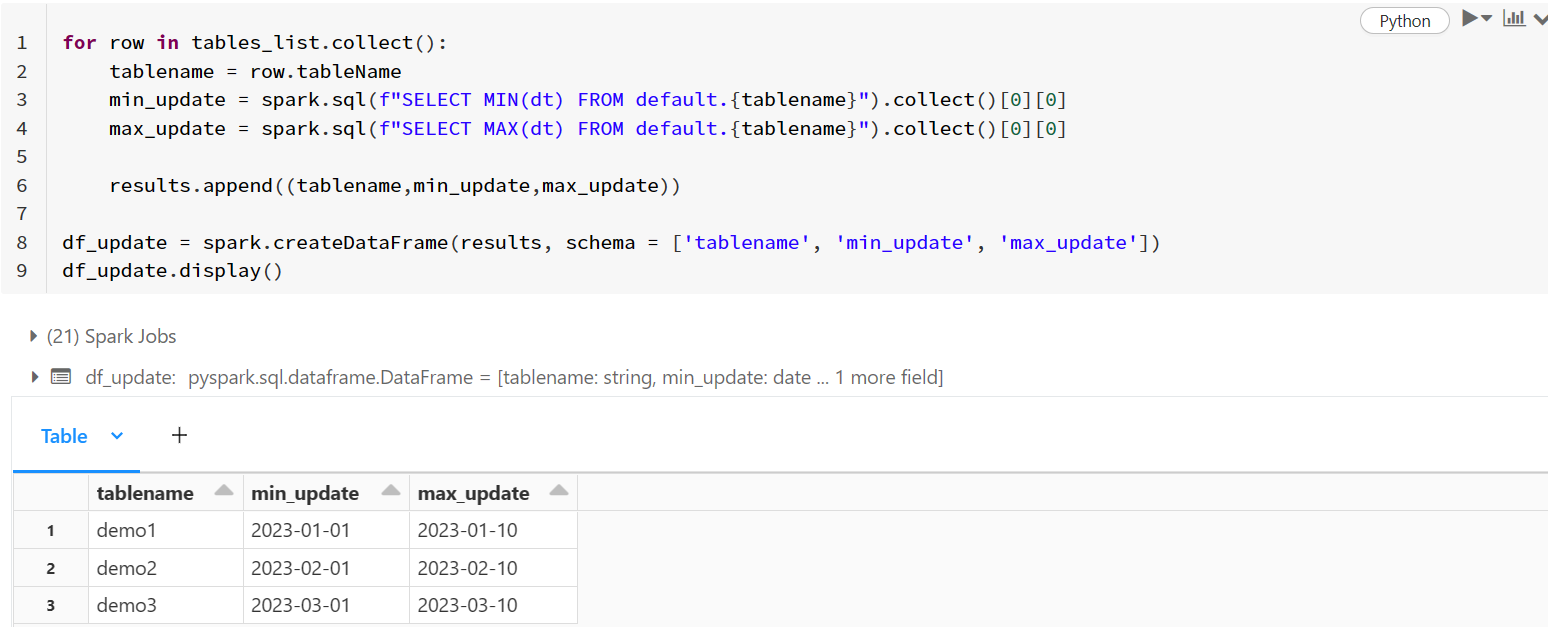
- Now I have used the append operation on result array inside the loop and got expected result.
for row in tables_list.collect():
tablename = row.tableName
#default is the name of my database and dt is date column
min_update = spark.sql(f"SELECT MIN(dt) FROM default.{tablename}").collect()[0][0]
max_update = spark.sql(f"SELECT MAX(dt) FROM default.{tablename}").collect()[0][0]
results.append((tablename,min_update,max_update))
df_update = spark.createDataFrame(results, schema = ['tablename', 'min_update', 'max_update'])
df_update.display()