How do I go from:
[In]: df = pd.DataFrame({
'col1': [100, np.nan, np.nan, 100, np.nan, np.nan],
'col2': [np.nan, 100, np.nan, np.nan, 100, np.nan]
})
df
[Out]: col1 col2
0 100 NaN
1 NaN 100
2 NaN NaN
3 100 NaN
4 NaN 100
5 NaN NaN
To:
[Out]: col1 col2
0 100 NaN
1 100 100
2 100 100
3 100 100
4 NaN 100
5 NaN NaN
My current approach is a to apply a custom method that works on one column at a time:
[In]: def ffill_last_valid(s):
last_valid = s.last_valid_index()
s = s.ffill()
s[s.index > last_valid] = np.nan
return s
df.apply(ffill_last_valid)
But it seems like an overkill to me. Is there a one-liner that works on the dataframe directly?
Note on accepted answer:
See the accepted answer from mozway below.
I know it's a tiny dataframe but:
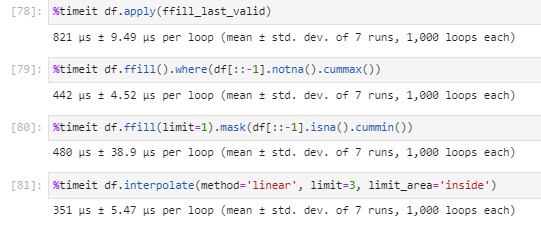
CodePudding user response:
You can ffill, then keep only the values before the last stretch of NaN with a combination of where and notna/reversed-cummax:
out = df.ffill().where(df[::-1].notna().cummax())
variant:
out = df.ffill().mask(df[::-1].isna().cummin())
Output:
col1 col2
0 100.0 NaN
1 100.0 100.0
2 100.0 100.0
3 100.0 100.0
4 NaN 100.0
5 NaN NaN
interpolate:
In theory, df.interpolate(method='ffill', limit_area='inside') should work, but while both options work as expected separately, for some reason it doesn't when combined (pandas 1.5.2). This works with df.interpolate(method='zero', limit_area='inside'), though.