I am trying to get the job post data from LinkedIn using Selenium for a practice project.
I am getting the list of job card elements and the job IDs and clicking on each of them to load the job post, and then obtaining the job details.
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
login_page_link = 'https://www.linkedin.com/login'
search_page_link = 'https://www.linkedin.com/jobs/search/?geoId=101452733&keywords=data analyst&location=Australia&refresh=true'
job_list_item_class = 'jobs-search-results__list-item'
job_title_class = 'jobs-unified-top-card__job-title'
company_name_class = 'jobs-unified-top-card__company-name'
def get_browser_driver():
browser = webdriver.Chrome()
# maximise browser window
browser.maximize_window()
return browser
def login_to_linkedin(browser):
browser.get(login_page_link)
# enter login credentials
browser.find_element(by=By.ID, value=username_id).send_keys("[email protected]")
browser.find_element(by=By.ID, value=password_id).send_keys("pwd")
login_btn = browser.find_element(by=By.XPATH, value=login_btn_xpath)
# attempt login
login_btn.click()
# wait till new page is loaded
time.sleep(2)
def get_job_post_data(browser):
# list to store job posts
job_posts = []
# get the search results list
job_cards = browser.find_elements(by=By.CLASS_NAME, value=job_list_item_class)
for job_card in job_cards:
job_id = job_card.get_attribute('data-occludable-job-id')
# dict to store each job post
job_dict = {}
# scroll job post into view
browser.execute_script("arguments[0].scrollIntoView();", job_card)
# click to load each job post
job_card.click()
time.sleep(5)
# get elements from job post by css selector
job_dict['Job ID'] = job_id
job_dict['Job title'] = get_element_text_by_classname(browser, job_title_class)
job_dict['Company name'] = get_element_text_by_classname(browser, company_name_class)
job_posts.append(job_dict)
return job_posts
def get_element_text_by_classname(browser, class_name):
return browser.find_element(by=By.CLASS_NAME, value=class_name).text
browser = get_browser_driver()
login_to_linkedin(browser)
load_search_results_page(browser)
jobs_list = get_job_post_data(browser)
jobs_df = pd.DataFrame(all_jobs)
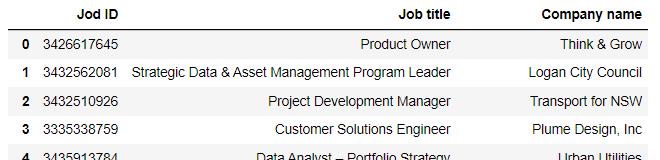
When I try to scrape all job posts in the page, it gives me repeated (duplicated) and empty results as shown in the images below. The job ID, keeps updating and changing but the job details get randomly duplicated.
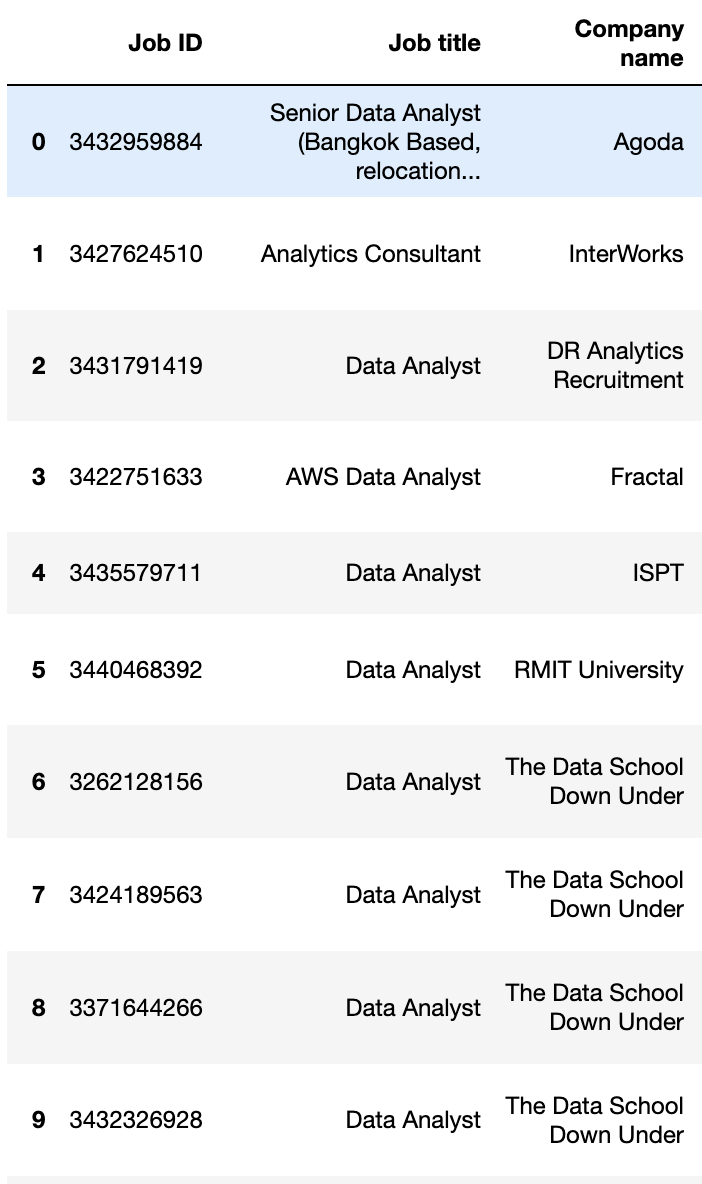
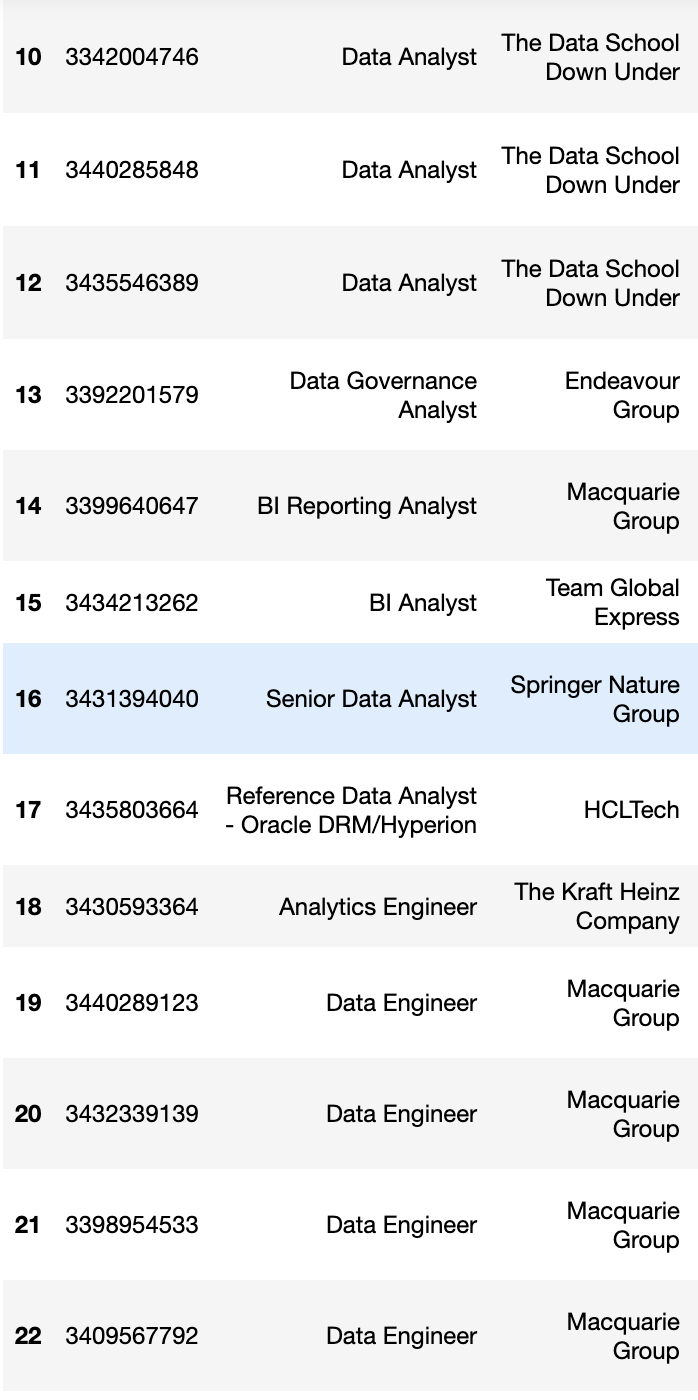

I would be much thankful if you could suggest any ideas as to why this is happening and how to fix this error.
CodePudding user response:
It should be worth noting that scraping LinkedIn Data is against the company's terms of service, which may result in your account being blocked.
That being said, check these common things:
The for loop in the get_job_post_data function is iterating through the same set of job cards multiple times, resulting in duplicate results.
The job_cards variable is not being initialized correctly, resulting in an empty list.
The load_search_results_page function is not defined in the code.
The get_element_text_by_classname function may not be able to find the element by class name, leading to empty results.
And Finally: Due to LinkedIn's dynamic website and anti-scraping policy, the elements that you are trying to scrape may not be loaded properly.(as stated initially)
CodePudding user response:
There is no need to click on the cards to get the job titles and company names, since they are already available in the list.
# load all 25 cards
cards = []
while len(cards) < 25:
cards = driver.find_elements(By.CSS_SELECTOR, '.job-card-container')
driver.execute_script('arguments[0].scrollIntoView({block: "center", behavior: "smooth"});', cards[-1])
time.sleep(0.5)
# store details
ids = [card.get_attribute('data-job-id') for card in cards]
titles = [title.text for title in driver.find_elements(By.CSS_SELECTOR, '.job-card-list__title')]
companies = [company.text for company in driver.find_elements(By.CSS_SELECTOR, '.job-card-container__company-name')]
# print results
pd.DataFrame({'Job ID':ids, 'Job title':titles, 'Company name':companies})
output