I have a GroupBy Data Frame that is similar to this one:
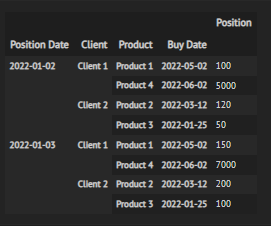
I want to create a column named PL as the difference between the Position of the same Product of the same Client buyed on the same day with the previous day's position. Also the first dates should have PL = 0.
The dataframe should look like this
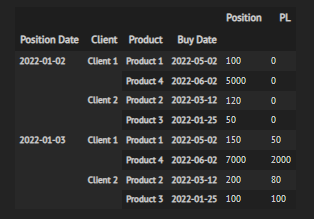
Edit: the unstacked dataframe looks like this:
{kind=link}
Dataframe constructor:
data = {'Client': ['Client 1', 'Client 1', 'Client 2', 'Client 2', 'Client 1', 'Client 1', 'Client 2', 'Client 2'],
'Position Date': ['2022-01-02', '2022-01-02', '2022-01-02', '2022-01-02', '2022-01-03', '2022-01-03', '2022-01-03', '2022-01-03'],
'Product': ['Product 1', 'Product 4', 'Product 2', 'Product 3', 'Product 1', 'Product 4', 'Product 2', 'Product 3'],
'Buy Date': ['2022-05-02', '2022-06-02', '2022-03-12', '2022-01-25', '2022-05-02', '2022-06-02', '2022-03-12', '2022-01-25'],
'Position': [100, 5000, 120, 50, 150, 7000, 200, 100]}
df = pd.DataFrame(data).set_index(['Position Date', 'Client', 'Product', 'Buy Date'])
CodePudding user response:
You can use groupby with level as parameter of your index levels:
df['PL'] = df.groupby(level=['Client', 'Product', 'Buy Date']).diff().fillna(0)
print(df)
# Output
Position PL
Position Date Client Product Buy Date
2022-01-02 Client 1 Product 1 2022-05-02 100 0.0
Product 4 2022-06-02 5000 0.0
Client 2 Product 2 2022-03-12 120 0.0
Product 3 2022-01-25 50 0.0
2022-01-03 Client 1 Product 1 2022-05-02 150 50.0
Product 4 2022-06-02 7000 2000.0
Client 2 Product 2 2022-03-12 200 80.0
Product 3 2022-01-25 100 50.0