Humble greetings and welcome to anyone willing to spend time here. I shall introduce myself as a very green student of data science and also python. This thread is meant to gain insight from rather more fortunate minds capable of deeper understanding within the realm of python.
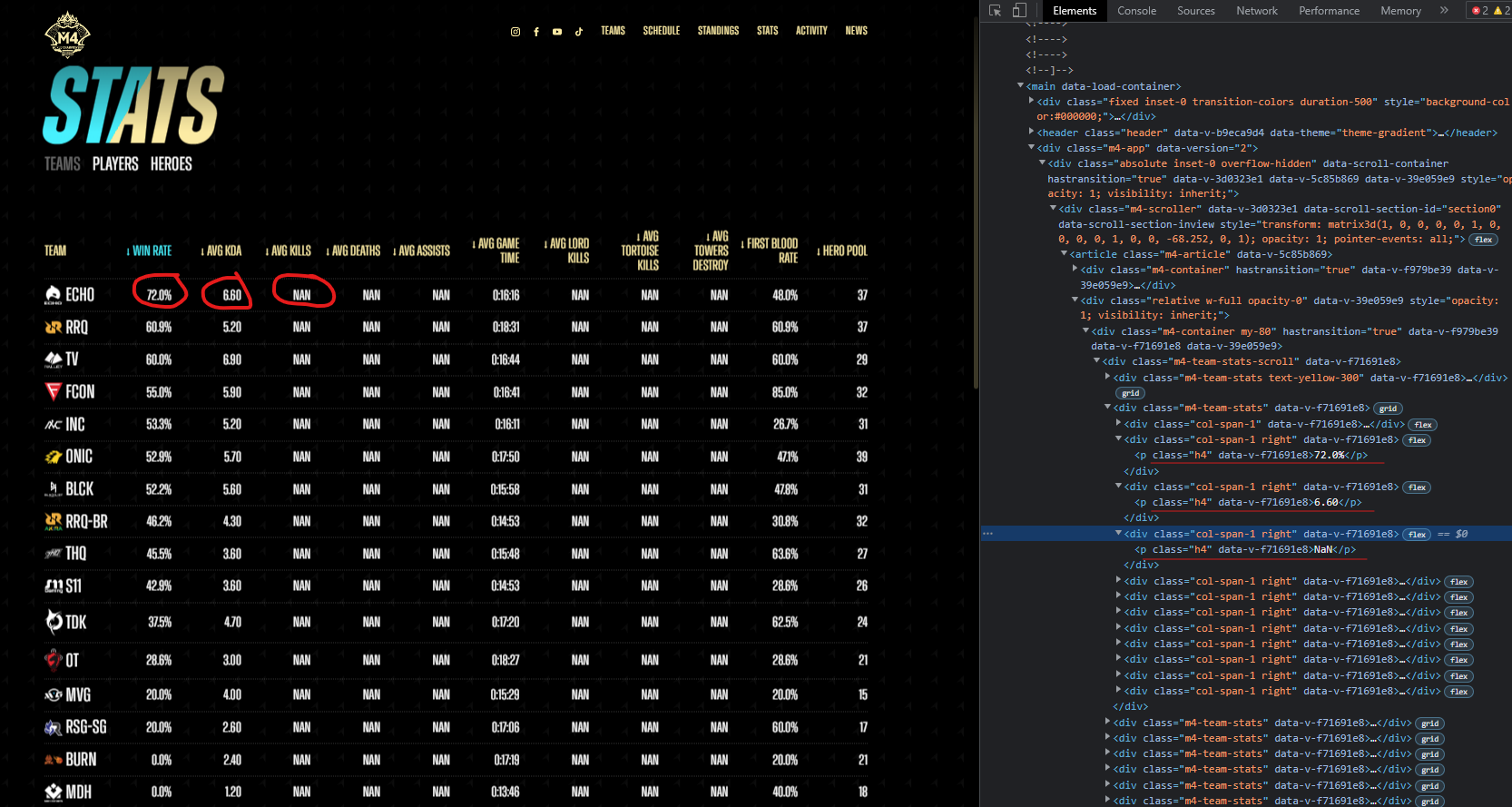
As we can see, the value for each row itself could be found easily on the page inspection. But it seems that they all are using the same class name. As for now, i'm afraid i couldnt even find the right keyword to search for any working method in google.
These are the codes that i've tried. They dont work and embaressing, but i have to show it anyway. Ive tried fiddling by adding .content, .text, find, find_all, but i understand that my failure lies at even deeper fundamental core.
from bs4 import BeautifulSoup
import requests
from csv import writer
import pandas as pd
url= 'https://m4.mobilelegends.com/stats'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
lists = soup.find('div', class_="m4-team-stats-scroll")
with open('m4stats_team.csv', 'w', encoding='utf8', newline='') as f:
thewriter = writer(f)
header = ['Team', 'Win Rate', 'Average KDA', 'Average Kills', 'average Deaths', 'Average Assists', 'Average Game Time', 'Average Lord Kills', 'Average Tortoise Kills', 'Average Towers Destroy', 'First Blood Rate', 'Hero Pool']
thewriter.writerow(header)
for list in lists:
team = list.find_all('p', class_="h3 pl-5 whitespace-nowrap hidden xl:block")
awr = list.find_all('p', class_="h4")
akda = list.find('p', class_="h4").text
akill = list.find('p', class_="h4").text
adeath = list.find('p', class_="h4").text
aassist = list.find('p', class_="h4").text
atime = list.find('p', class_="h4").text
aalord = list.find('p', class_="h4").text
atortoise = list.find('p', class_="h4").text
atower = list.find('p', class_="h4").text
firstblood = list.find('p', class_="h4").text
hrpool = list.find('p', class_="h4").text
info = [team, awr, akda, akill, adeath, aassist, atime, aalord, atortoise, atower, firstblood, hrpool]
thewriter.writerow(info)
pd.read_csv('m4stats_team.csv').head()
What am i expecting: Any kind of insight. Whether if it's clue, keyword, code snippet, i do appreciate and mostfully thankful for any kind of guidance. I am not asking for somehow getting the complete scrapped CSV, as i couldve done it manually. At these point i want to be able to do basic webscraping myself.
CodePudding user response:
You can iterate over rows in the table and its items.
from bs4 import BeautifulSoup
import requests
page = requests.get('https://m4.mobilelegends.com/stats')
page.raise_for_status()
page = BeautifulSoup(page.content)
table = page.find("div", class_="m4-team-stats-scroll")
with open("table.csv", "w") as file:
for row in table.find_all("div", class_="m4-team-stats"):
items = row.find_all("div", class_="col-span-1")
# write into file in csv format, use map to extract text from items
file.write(",".join(map(lambda item: item.text, items)) "\n")
Display output:
import pandas as pd
df = pd.read_csv("table.csv")
print(df)
# Outputs:
"""
Team ↓Win Rate ... ↓First Blood Rate ↓Hero pool
0 echo 72.0% ... 48.0% 37
1 rrq 60.9% ... 60.9% 37
2 tv 60.0% ... 60.0% 29
3 fcon 55.0% ... 85.0% 32
4 inc 53.3% ... 26.7% 31
5 onic 52.9% ... 47.1% 39
6 blck 52.2% ... 47.8% 31
7 rrq-br 46.2% ... 30.8% 32
8 thq 45.5% ... 63.6% 27
9 s11 42.9% ... 28.6% 26
10 tdk 37.5% ... 62.5% 24
11 ot 28.6% ... 28.6% 21
12 mvg 20.0% ... 20.0% 15
13 rsg-sg 20.0% ... 60.0% 17
14 burn 0.0% ... 20.0% 21
15 mdh 0.0% ... 40.0% 18
[16 rows x 12 columns]
"""