I am making a pipeline with sklearn to handle my dataset, when trying to use OneHotEncoder (to transform not-numeric attributes into numeric ones) as one of pipeline's step - it returns the wrong shape size array.
The shape of original dataset is (8693, 14) and final dataset returned using pipeline must have the same size. Generally if I don't use OneHotEncoder in pipeline - it returns normal shape size array, but when I add it - shape is ruined and it's wrong.
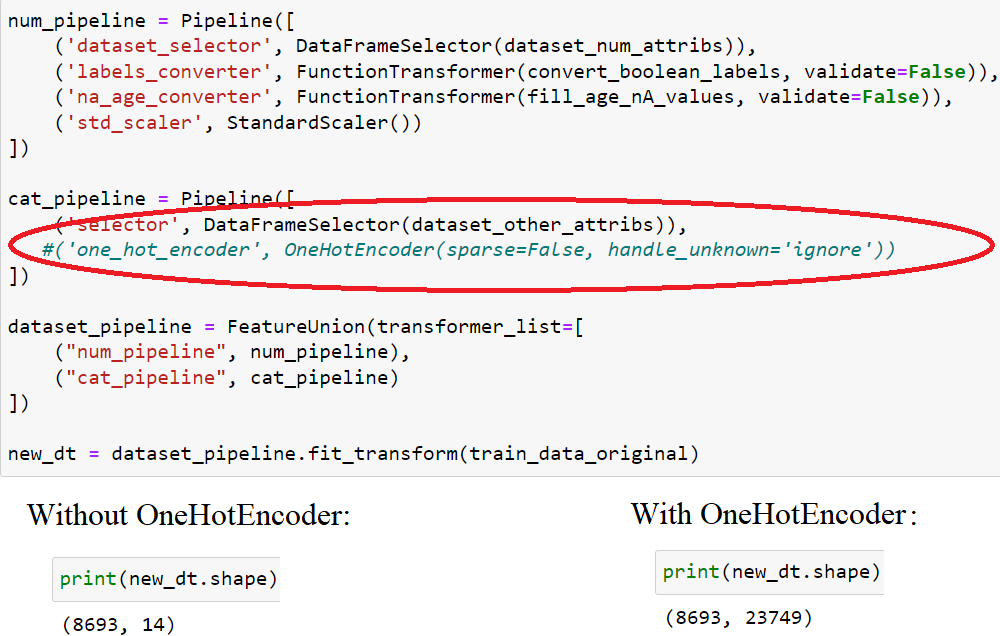
Can you help please? Already tried OneHotEncoder parameters, 'toarray' method, 'resize' method and they do not solve the problem.
CodePudding user response:
OneHotEncoder creates one column per category, to map a categorical/string column to a number you can use OrdinalEncoder instead.