Community!
I've been stuck on solving a problem for quite a while now. I guess it's a simple error in my for-loop, but I can't seem to locate where it fails.
What am I trying to accomplish?
- Loop through a dataset (from .csv) in format shown below.
- Assess limits provided in the
# Capacity constraints-part. - For each line in the list of data, check level-category (
level_capacity = {"HIGH": 30, "MED": 100, "LOW": 100}. The "Level" column contains one of the three as defined with limits in dictlevel_capacity. - If the item has not been assigned a week (Column 'Week' Is None), and level_capacity are for the Level of the row, then assign it to
current_weekand write it to column 'Week'. - This loop should repeat until all keys in
level_capacitiesmeet the requirement specified inlevel_capacity. - When
level_capacities.values()==level_capacity, incrementcurrent_weekby 1 (moving to next week) and repeat the process.
What's not working - output
I'm trying to achieve this, but it seems to be incomplete. Somehow the code stops end breaks the loop when the DateFrame has been fully looped through. My goal is to have it keep looping, until all rows have been assigned a week in column 'Week', and all weeks have maximum quantity (i.e. level_capacity == level_capacities.values()
For the sake of keeping the question compressed, below you'll find the first 8 rows of my .csv-file:
Week Quantity Level
1 1 LOW
19 4 LOW
39 1 LOW
4 2 HIGH
9 18 MED
12 23 HIGH
51 11 MED
The actual dataset contains 1703 rows of data. I've ran the code, and extracted to Excel to see the distribution:
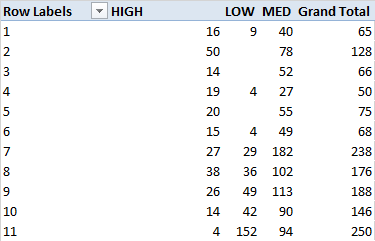
However, as you can see the distribution does not align with the limits specified above. Any help would be greatly appriciated!
Code
import pandas as pd
# Define capacity constraints
level_capacity = {"HIGH": 30, "MED": 100, "LOW": 100}
weekly_capacity = sum(level_capacity.values())
# Init variables
current_week = 1
current_weekly_capacity = 0
level_capacities_met = {"HIGH": False, "MED": False, "LOW": False}
# Load data to DataFrame
d = {'Week': [1, 19, 39, 4, 9, 12, 51], 'Quantity': [1, 4, 1, 2, 18, 23, 11], 'Level': ['LOW','LOW','LOW','HIGH','MED','HIGH','MED']}
data = pd.DataFrame(data=d)
max_week = data["Week"].max()
while current_week <= max_week:
for index, row in data.iterrows():
# Check if the level capacity is met
if not level_capacities_met.get(row["Level"], False):
if current_weekly_capacity row["Quantity"] <= weekly_capacity:
# Assign the current week
data.at[index, "Week"] = current_week
current_weekly_capacity = row["Quantity"]
if current_weekly_capacity == weekly_capacity:
level_capacities_met[row["Level"]] = True
else:
# Move to next week and reset capacities
current_week = 1
current_weekly_capacity = 0
elif current_weekly_capacity row["Quantity"] <= weekly_capacity:
# Assign the current week
data.at[index, "Week"] = current_week
current_weekly_capacity = row["Quantity"]
# check if all level capacities are met
if all(level_capacities_met.values()):
current_week = 1
current_weekly_capacity = 0
level_capacities_met = {"HIGH": False, "MED": False, "LOW": False}
print (data)
CodePudding user response:
My impression is that the code provided in the question has (at least one) error in reasoning and also overcomplicates things.
The main thing is probably that the current_weekly_capacity is checked against a total weekly_capacity. But this total weekly_capacity does not take into account if the capacity of the levels (HIGH, MEDIUM, LOW) is reached.
Think about the following scenario as an (made up) example: You iterate through a data frame. The weekly_capacity is not yet reached (say the current value is 100) and also level_capacities_met = {"HIGH": False, ...}. The current row has a Week value of None, a level of HIGH and a quantity of 50. Then the capacity would be happily planned for the current week, even though it exceeds the available capacity for level HIGH.
Instead of counting a current_weekly_capacity I would suggest counting the capacity of each level separately using current_weekly_capacities = {"HIGH": 0, "MED": 0, "LOW": 0} (see also the additional comments in the code).
import pandas as pd
# Define capacity constraints
level_capacity = {"HIGH": 30, "MED": 100, "LOW": 100}
#weekly_capacity = sum(level_capacity.values()) # not required
# Load data to DataFrame
data = {
'Week': [1, 19, 39, 4, 9, 12, 51, 39, 39, 39, 39, 39, 40, 40, 41, 41],
'Quantity': [1, 4, 1, 2, 18, 23, 11, 1, 10, 8, 10, 5, 3, 1, 40, 2],
'Level': ["LOW", "LOW", "LOW", "HIGH", "MED", "HIGH", "MED", "HIGH", "LOW", "LOW", "LOW", "HIGH", "HIGH", "HIGH", "HIGH", "HIGH" ]
}
df = pd.DataFrame(data)
#df.at["Week"] = None # ?? --> replaced by df["Week"] = None (after getting value for max_week)
max_week = df["Week"].max()
df["Week"] = None
Check if the sum of Quantity for any level and any week exceeds the level_capacity:
g = df.groupby(by=['Week', 'Level']).sum().reset_index()
g.rename(columns={'Quantity':'sum'}, inplace=True)
def set_level_capacity(row):
if row['Level'] == 'HIGH':
return 30
if row['Level'] == 'MED':
return 100
if row['Level'] == 'LOW':
return 100
return -1
g['level_capacity'] = g.apply(lambda row: set_level_capacity(row), axis=1)
print(g[g['sum'] > g['level_capacity']])
Now the planning logic (needs to be revised due to some additional information to the question):
# Init variables for loop
current_week = 1
current_weekly_capacities = {"HIGH": 0, "MED": 0, "LOW": 0} # instead of current_weekly_capacity = 0
level_capacities_met = {"HIGH": False, "MED": False, "LOW": False} # (1)
while current_week <= max_week:
for index, row in df.iterrows():
# Check if already assigned to a week
if pd.isna(row["Week"]):
level = row["Level"]
# Check if the level capacity is met
if not level_capacities_met[level]: # (2)
if current_weekly_capacities[level] row["Quantity"] <= level_capacity[level]: # (3)
# Assign the current week
df.at[index, "Week"] = current_week
current_weekly_capacities[level] = row["Quantity"] # (4)
if current_weekly_capacities[level] == level_capacity[level]:
level_capacities_met[level] = True
if all(level_capacities_met.values()): # (5)
current_week = 1
current_weekly_capacity = 0
level_capacities_met = {"HIGH": False, "MED": False, "LOW": False}
break
# removed/not required
#else:
# # Move to next week and reset capacities
# current_week = 1
# current_weekly_capacity = 0
# (?? - not required) Level capacities are met but current weekly capacity row capacity < weekly capacity
#elif current_weekly_capacity row["Quantity"] <= weekly_capacity:
# # Assign the current week
# df.at[index, "Week"] = current_week
# current_weekly_capacity = row["Quantity"]
# (6) moved logic up (see 5)
#if all(level_capacities_met.values()):
# current_week = 1
# current_weekly_capacity = 0
# level_capacities_met = {"HIGH": False, "MED": False, "LOW": False}
# (7) current_week should always be increased after iterating over the complete data frame to avoid an infinite loop
current_week = 1
current_weekly_capacities = {"HIGH": 0, "MED": 0, "LOW": 0}
level_capacities_met = {"HIGH": False, "MED": False, "LOW": False}
(1) I kept the kept the level_capacities_met, though the variable is not really required (--> could be replaced by checking if current_weekly_capacities[level] of a given level is below the capacity level).
(2) I suggest using level_capacities_met[level] instead of the get operator level_capacities_met.get(level, False). This way the code throws an error in case the level is unknown (--> error in database).
(3) Check the capacity of the current level (not a capacity value the summaries all levels).
(4) Add the quantity to the current specific level.
(5) Restart iterating the data frame if all weekly capacities are met