I have 2 columns that look a little like this:
| Column A | Column B | Column C |
|---|---|---|
| ABC | {"ABC":1.0,"DEF":24.0,"XYZ":10.50,} | 1.0 |
| DEF | {"ABC":1.0,"DEF":24.0,"XYZ":10.50,} | 24.0 |
I need a select statement to create column C - the numerical digits in column B that correspond to the letters in Column A. I have got as far as finding the starting point of the numbers I want to take out. But as they have different character lengths I can't count a length, I want to extract the characters from the calculated starting point( below) up to the next comma.
STRPOS(Column B, Column A) 5 Gives me the correct character for the starting point of a SUBSTRING query, from here I am lost. Any help much appreciated.
NB, I am using google Big Query, it doesn't recognise CHARINDEX.
CodePudding user response:
You can use a regular expression as well.
WITH sample_table AS (
SELECT 'ABC' ColumnA, '{"ABC":1.0,"DEF":24.0,"XYZ":10.50,}' ColumnB UNION ALL
SELECT 'DEF', '{"ABC":1.0,"DEF":24.0,"XYZ":10.50,}' UNION ALL
SELECT 'XYZ', '{"ABC":1.0,"DEF":24.0,"XYZ":10.50,}'
)
SELECT *,
REGEXP_EXTRACT(ColumnB, FORMAT('"%s":([0-9.] )', ColumnA)) ColumnC
FROM sample_table;
Query results
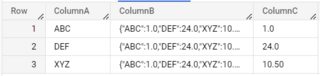
[Updated]
Regarding @Bihag Kashikar's suggestion: sinceColumnB is an invalid json, it will not be properly parsed within js udf like below. If it's a valid json, js udf with json key can be an alternative of a regular expression. I think.
CREATE TEMP FUNCTION custom_json_extract(json STRING, key STRING)
RETURNS STRING
LANGUAGE js AS """
try {
obj = JSON.parse(json);
}
catch {
return null;
}
return obj[key];
""";
SELECT custom_json_extract('{"ABC":1.0,"DEF":24.0,"XYZ":10.50,}', 'ABC') invalid_json,
custom_json_extract('{"ABC":1.0,"DEF":24.0,"XYZ":10.50}', 'ABC') valid_json;
Query results

CodePudding user response:
take a look at this post too, this shows using js udf and with split options
Error when trying to have a variable pathsname: JSONPath must be a string literal or query parameter