I'm trying to add numbers that have the unit prefixes appended at the end (mili, micro, nano, pico, etc). For example, we have these two columns below:
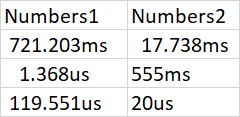
Obviously doing something like =A2 A3 A4 and =B2 B3 B4 would not work. How would you resolve this? Thanks
CodePudding user response:
Assuming you don't have excel version constraints, per the tags listed in your question. Put all the suffixes as delimiters inside {} delimited by a comma as follow in TEXTSPLIT, then define the conversion rules in XLOOKUP:
=BYCOL(A2:B4, LAMBDA(col, LET(nums, 1*TEXTSPLIT(col,{"ms","us"},,1),
units, XLOOKUP(RIGHT(col,2), {"us";"ms"},{1;1000}), SUM(nums * units))))
The above formula converts the result to a common unit of microseconds (us), i.e. to the lower unit, so milliseconds get converted by multiplying by 1000. If the unit of measure was not found it returns #N/A, it can be customized by adding a fourth parameter to XLOOKUP. If you want the result in milliseconds, then replace: {1;1000} with {0.001;1} or VSTACK(10^-3;1) for example.
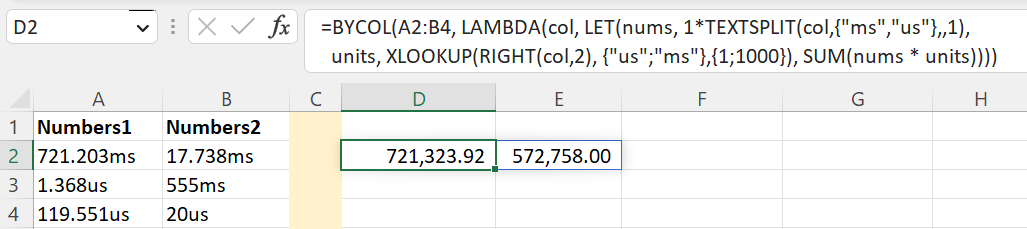
The previous formula assumes the unit of measure has two characters only. In case you would like to consider units of measure with a single character too, such as s for seconds. Replace RIGHT(col,2) with SUBSTITUTE(col, nums, "") this will extract the unit of measure. Then you need to include the conversion logic for this unit in the XLOOKUP function.
If you would like to have everything in seconds, you can use the trick of using power combined with the XMATCH index position, to generate the multiplier. I took the idea from this question: How to convert K, M, B formatted strings to plain numbers?, check the answer from @pgSystemTester (for Gsheet, but it can be adapted to Excel). I included nanoseconds too.
=BYCOL(A2:B4,LAMBDA(col,LET(nums,1*TEXTSPLIT(col,{"ms","us"},,1),
units, 1000^(-IFERROR(XMATCH(RIGHT(col,2), {"ms";"us";"ns"}),0)), SUM(nums * units))))
Under this approach, if the number doesn't have any unit it is assumed seconds, so the multiplier will be 1 (as a result of 1000^0)
Notes:
- In my initial version I used
INDEX, but as @P.b pointed out in the comments, it is not really necessary to remove the second empty column, instead, we can use theignore_emptyinput argument fromTEXTSPLIT. Thanks