I am working with a data frame that is written in wide format. Each book has a number of sales, but some quarters have null values because the book was not released before that quarter.
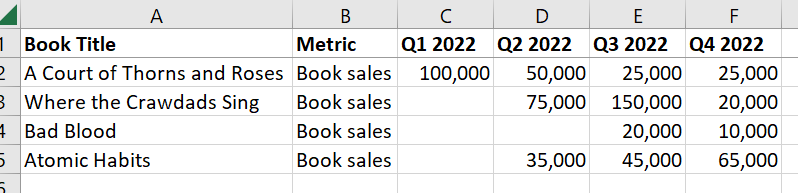
import pandas as pd
data = {'Book Title': ['A Court of Thorns and Roses', 'Where the Crawdads Sing', 'Bad Blood', 'Atomic Habits'],
'Metric': ['Book Sales','Book Sales','Book Sales','Book Sales'],
'Q1 2022': [100000,0,0,0],
'Q2 2022': [50000,75000,0,35000],
'Q3 2022': [25000,150000,20000,45000],
'Q4 2022': [25000,20000,10000,65000]}
df1 = pd.DataFrame(data)
What I want to do is find the first two available quarters for each title, and create a new dataframe with those values in two columns, like so:
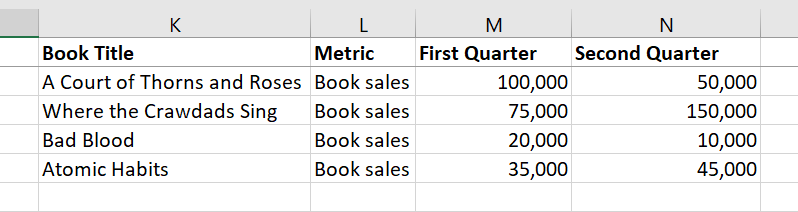
I've had a hard time finding what function would do this - can you point me in the right direction? Thank you!
CodePudding user response:
Some version of melt or stack would probably the the easiest way to go.
import pandas as pd
import numpy as np
data = {'Book Title': ['A Court of Thorns and Roses', 'Where the Crawdads Sing', 'Bad Blood', 'Atomic Habits'],
'Metric': ['Book Sales','Book Sales','Book Sales','Book Sales'],
'Q1 2022': [100000,np.nan,np.nan,np.nan],
'Q2 2022': [50000,75000,np.nan,35000],
'Q3 2022': [25000,150000,20000,45000],
'Q4 2022': [25000,20000,10000,65000]}
key_cols = ['Book Title','Metric']
new_cols = ['First Quarter','Second Quarter']
df1[new_cols] = (df1.set_index(key_cols)
.stack()
.groupby(level=0)
.head(2)
.values
.astype(int)
.reshape(len(df1),-1)
)
df1 = df1[key_cols new_cols]
Output
Book Title Metric First Quarter Second Quarter
0 A Court of Thorns and Roses Book Sales 100000 50000
1 Where the Crawdads Sing Book Sales 75000 150000
2 Bad Blood Book Sales 20000 10000
3 Atomic Habits Book Sales 35000 45000