I need to change the text variable in the data set below. Namely, each row has categorical values in the object format that need to be changed, depending on the last character in the data set. Below you can see my dataset.
import pandas as pd
import numpy as np
data = {
'stores': ['Lexinton1','ROYAl2','Mall1','Mall2','Levis1','Levis2','Shark1','Shark','Lexinton'],
'quantity':[1,1,1,1,1,1,1,1,1]
}
df = pd.DataFrame(data, columns = ['stores',
'quantity'
])
df
Now I want to change this data depending on the last character. For example, if the last charter is number 1 then I want to put the word open, if is number 2 then I want to put closed.If is not a number then I don't put anything and the text will be the same. Below you can output that is desirable
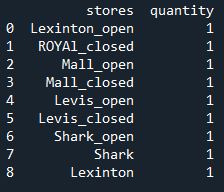
CodePudding user response:
You can approach this by using pandas.Series.str and pandas.Series.map.
dmap = {1: "_open", 2: "_close"}
suffix = pd.to_numeric(df["stores"].str[-1], errors="coerce").map(dmap).fillna("")
df["stores"] = df["stores"].str[:-1].add(suffix)
Or simply by using pandas.Series.replace :
df["stores"] = df["stores"].replace({"1$": "_open", "2$": "_close"}, regex=True)
Output :
print(df)
stores quantity
0 Lexinton_open 1
1 ROYAl_close 1
2 Mall_open 1
3 Mall_close 1
4 Levis_open 1
5 Levis_close 1
6 Shark_open 1
7 Shar 1
8 Lexinto 1
CodePudding user response:
You can try this.
import pandas as pd
import numpy as np
data = {
'stores': ['Lexinton1','ROYAl2','Mall1','Mall2','Levis1','Levis2','Shark1','Shark','Lexinton'],
'quantity':[1,1,1,1,1,1,1,1,1]
}
for i in range(len(data['stores'])):
if data['stores'][i][-1] == '1':
data['stores'][i] = data['stores'][i][:-1] '_open'
elif data['stores'][i][-1] == '2':
data['stores'][i] = data['stores'][i][:-1] '_closed'
df = pd.DataFrame(data, columns = ['stores',
'quantity'
])
df