I am completely new to Jupiter Notebook, Python, Webscraping and stuff. I looked and different answers but no one seems to has the same problem (and I am not good in adapting "a similar" approach, change it a bit so I can use it for my purpose).
I want to create a data grid with all existing HTML tags. As source I am using MDN docs. It works find to get all Tags with Beautiful Soup but I struggle to go any further with this data.
Here is the code from fetching the data with beautiful soup
from bs4 import BeautifulSoup
import requests
url = "https://developer.mozilla.org/en-US/docs/Web/HTML/Element"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
get_nav_tag = soup.find("nav", class_="sidebar-inner")
get_second_div = nav_tag.find_all("div")[2]
get_ol = get_second_div.find("ol")
get_li = get_second_div.find_all("li", class_="toggle")[3]
tag_list = get_li.find_all("code")
print("There are currently", len(tag_list), "tags.")
for tags in tag_list:
print(tags.text)

The list is already sorted.
Now I work with Pandas to create a dataframe
import pandas as pd
tag_data = []
for tag in tag_list:
tag_data.append({"Tags": tag.text})
df = pd.DataFrame(tag_data)
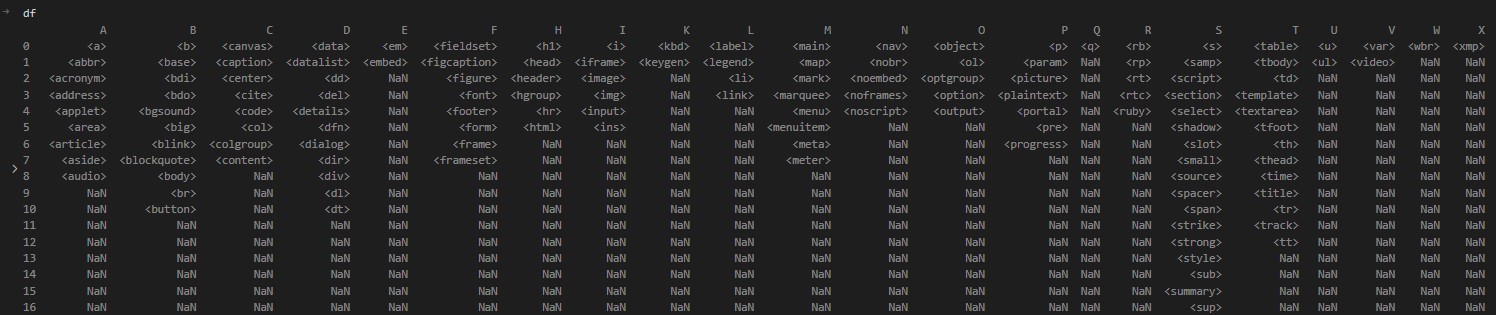
df
The output looks like

QUESTION
How do I create a dataframe where there are columns for each character and the elements are listed under each column?
Like:
A B C
1 <a> <b> <caption>
2 <abbr> <body> <code>
3 <article> .. ...
4 ... ... ...
How do I separate this list in more list corresponding to each elements first letter? I guess I will need it for further interactions as well, like creating graphs as such. E.g. to show in a bar chart, how many tags starting with "a", "b" etc exists.
Thank you!
CodePudding user response:
The code below should do the work.
df['first_letter'] = df.Tags.str[1]
tag_matrix = pd.DataFrame()
for letter in df.first_letter.unique():
# Create a pandas series whose name matches the first letter of the tag and contains tags starting with the letter
matching_tags = pd.Series(df[df.first_letter==letter].reset_index(drop=True).Tags, name=letter)
# Append the series to the tag_matrix
tag_matrix = pd.concat([tag_matrix, matching_tags], axis=1)
tag_matrix
Here's a sample of the output:
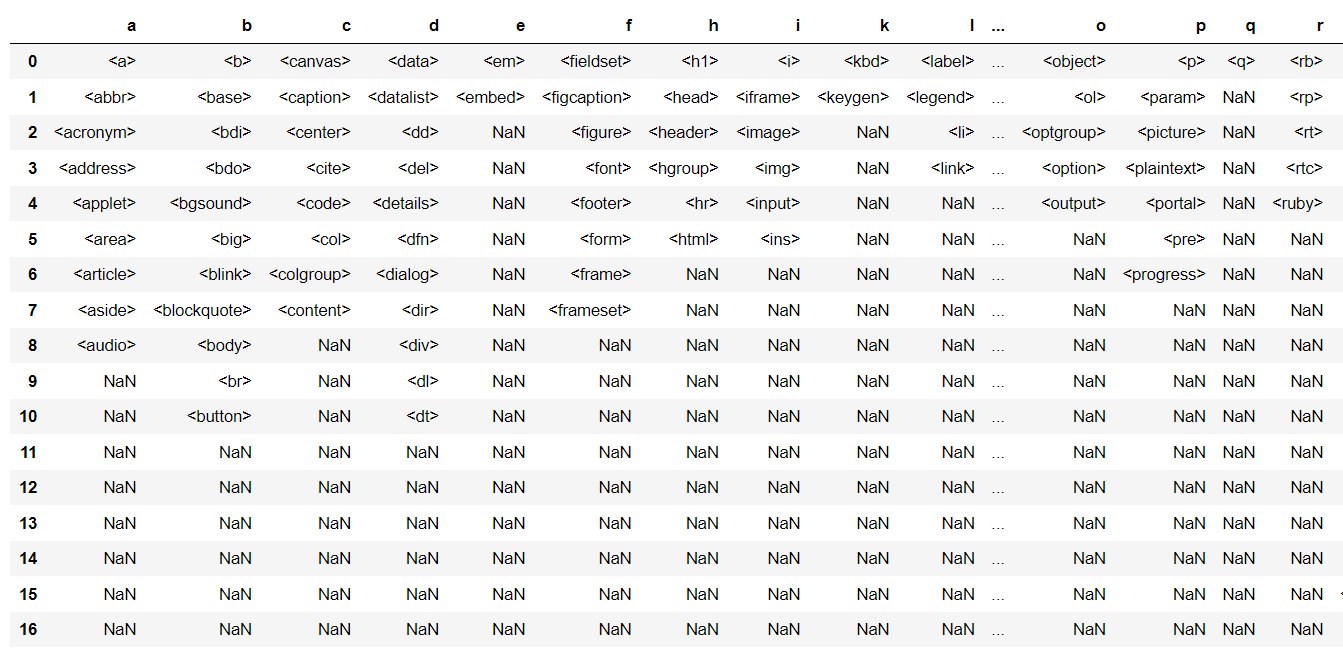
Note that you might want to do some additional cleaning, such as dropping duplicate tags or converting to lower case.
CodePudding user response:
You can use pivot and concat methods to achieve this
df["letter"] = df["Tags"].str[1].str.upper()
df = df.pivot(columns="letter", values="Tags")
df = pd.concat([df[c].dropna().reset_index(drop=True) for c in df.columns], axis=1)
This gives