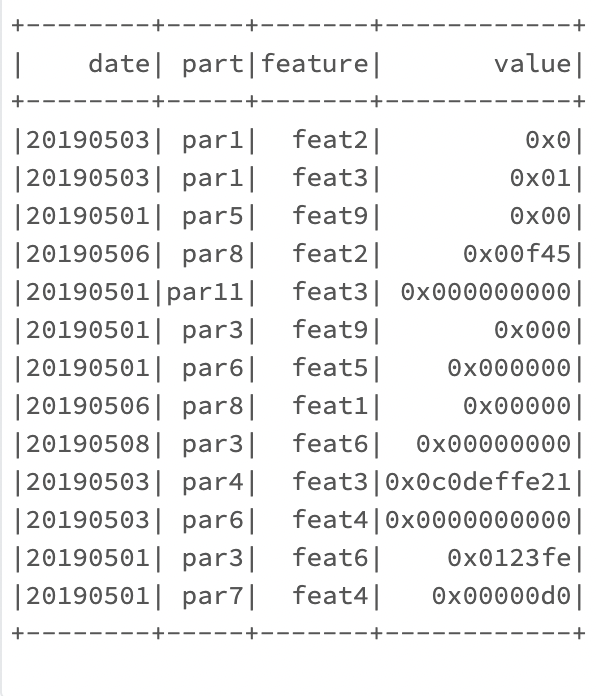
I have a huge dataframe similar to this:
l = [('20190503', 'par1', 'feat2', '0x0'),
('20190503', 'par1', 'feat3', '0x01'),
('date', 'part', 'feature', 'value'),
('20190501', 'par5', 'feat9', '0x00'),
('20190506', 'par8', 'feat2', '0x00f45'),
('date', 'part', 'feature', 'value'),
('20190501', 'par11', 'feat3', '0x000000000'),
('date', 'part', 'feature', 'value'),
('20190501', 'par3', 'feat9', '0x000'),
('20190501', 'par6', 'feat5', '0x000000'),
('date', 'part', 'feature', 'value'),
('20190506', 'par8', 'feat1', '0x00000'),
('20190508', 'par3', 'feat6', '0x00000000'),
('20190503', 'par4', 'feat3', '0x0c0deffe21'),
('20190503', 'par6', 'feat4', '0x0000000000'),
('20190501', 'par3', 'feat6', '0x0123fe'),
('20190501', 'par7', 'feat4', '0x00000d0')]
columns = ['date', 'part', 'feature', 'value']
-------- ----- ------- ------------
| date| part|feature| value|
-------- ----- ------- ------------
|20190503| par1| feat2| 0x0|
|20190503| par1| feat3| 0x01|
| date| part|feature| value|
|20190501| par5| feat9| 0x00|
|20190506| par8| feat2| 0x00f45|
| date| part|feature| value|
|20190501|par11| feat3| 0x000000000|
| date| part|feature| value|
|20190501| par3| feat9| 0x000|
|20190501| par6| feat5| 0x000000|
| date| part|feature| value|
|20190506| par8| feat1| 0x00000|
|20190508| par3| feat6| 0x00000000|
|20190503| par4| feat3|0x0c0deffe21|
|20190503| par6| feat4|0x0000000000|
|20190501| par3| feat6| 0x0123fe|
|20190501| par7| feat4| 0x00000d0|
-------- ----- ------- ------------
It has rows that match to the header and I would want to drop all of them, so that the result would be:
-------- ----- ------- ------------
| date| part|feature| value|
-------- ----- ------- ------------
|20190503| par1| feat2| 0x0|
|20190503| par1| feat3| 0x01|
|20190501| par5| feat9| 0x00|
|20190506| par8| feat2| 0x00f45|
|20190501|par11| feat3| 0x000000000|
|20190501| par3| feat9| 0x000|
|20190501| par6| feat5| 0x000000|
|20190506| par8| feat1| 0x00000|
|20190508| par3| feat6| 0x00000000|
|20190503| par4| feat3|0x0c0deffe21|
|20190503| par6| feat4|0x0000000000|
|20190501| par3| feat6| 0x0123fe|
|20190501| par7| feat4| 0x00000d0|
-------- ----- ------- ------------
I tried to get rid of them with the method .distinct() but one is always left.
How can I do it?
CodePudding user response:
This would work (essentially chaining multiple filters, Spark will take care of merging them while creating physical plan)
for col in df.schema.names:
df=df.filter(F.col(col) != col)
df.show()
Input:
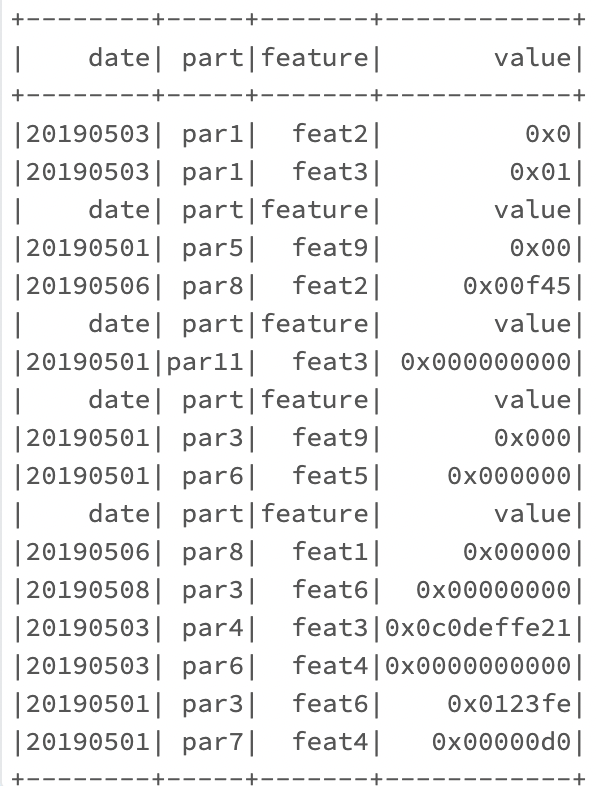
Output: