I want to spread the duplicated rows based on the key value (which is name of the car in this case). I've tried different ways to get the result I wanted. But I'm kinda stuck.
Say, this is the dataframe that I have.
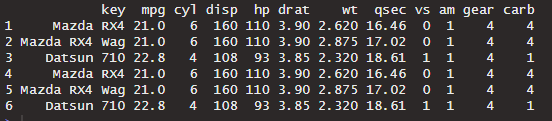
I want the result to be something like this. (used bind_cols() just to show my desired output)

So basically, I want to spread the duplicated rows based on the key value (which is name of the car in this case).
Thanks in advance..!
CodePudding user response:
This is a variant of Reshape multiple value columns to wide format:
Hasty data:
quux <- rbind(tibble::rownames_to_column(mtcars[1:3,], "key"), tibble::rownames_to_column(mtcars[1:3,], "key"))
dplyr
library(dplyr)
library(tidyr) # pivot_wider
quux %>%
group_by(key) %>%
mutate(rn = row_number()) %>%
ungroup() %>%
tidyr::pivot_wider(key, names_from=rn, values_from=-c(key, rn), names_vary = "slowest")
# # A tibble: 3 × 23
# key mpg_1 cyl_1 disp_1 hp_1 drat_1 wt_1 qsec_1 vs_1 am_1 gear_1 carb_1 mpg_2 cyl_2 disp_2 hp_2 drat_2 wt_2 qsec_2 vs_2 am_2 gear_2 carb_2
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 Mazda RX4 21 6 160 110 3.9 2.62 16.5 0 1 4 4 21 6 160 110 3.9 2.62 16.5 0 1 4 4
# 2 Mazda RX4 Wag 21 6 160 110 3.9 2.88 17.0 0 1 4 4 21 6 160 110 3.9 2.88 17.0 0 1 4 4
# 3 Datsun 710 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1