if i have the below dataframe
raw_data = {
'code': [1,1,1,1,2,2,2,2],
'Date': ['2022-01-04','2022-01-01', '2022-01-03','2022-01-02', '2022-01-08', '2022-01-07','2022-01-06','2022-01-05'],
'flag_check': [np.NaN, np.NaN, '11-33-24-33333' ,np.NaN, np.NaN,'11-55-24-33443' ,np.NaN, np.NaN],
'rank':[np.NaN, np.NaN, np.NaN, np.NaN, np.NaN, np.NaN, np.NaN, np.NaN]
}
df = pd.DataFrame(raw_data, columns=['code', 'Date','flag_check', 'rank'])
I need to do the following
1- rank the entries based on code then date
2- within the same code entries fill the rank column with series numbers 1,2,3 based on the code and the date.
3- check the value of a "flag_check" if it is not null then delete all rows after it
Expected result
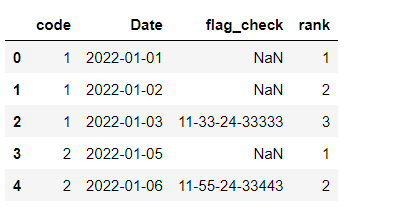
CodePudding user response:
Here's a way to do it:
df['rank'] = df.groupby(['code'])['Date'].rank(method='dense').astype(int)
df = df.sort_values(['code','Date'])
x = df.groupby('code')['flag_check'].apply(lambda x:x.shift().notna().cumsum())
df = df.loc[x[x==0].index,:].reset_index(drop=True)
Input:
code Date flag_check rank
0 1 2022-01-04 NaN NaN
1 1 2022-01-01 NaN NaN
2 1 2022-01-03 11-33-24-33333 NaN
3 1 2022-01-02 NaN NaN
4 2 2022-01-08 NaN NaN
5 2 2022-01-07 11-55-24-33443 NaN
6 2 2022-01-06 NaN NaN
7 2 2022-01-05 NaN NaN
Output:
code Date flag_check rank
0 1 2022-01-01 NaN 1
1 1 2022-01-02 NaN 2
2 1 2022-01-03 11-33-24-33333 3
3 2 2022-01-05 NaN 1
4 2 2022-01-06 NaN 2
5 2 2022-01-07 11-55-24-33443 3
CodePudding user response:
Annotated code
# Order by Date
s = df.sort_values('Date')
# rank the date column per code group
s['rank'] = s.groupby('code')['Date'].rank(method='dense')
# create boolean mask to identify the rows after the first non-null value
mask = s['flag_check'].notna()[::-1].groupby(df['code']).cummax()
Result
s[mask]
code Date flag_check rank
1 1 2022-01-01 NaN 1.0
3 1 2022-01-02 NaN 2.0
2 1 2022-01-03 11-33-24-33333 3.0
7 2 2022-01-05 NaN 1.0
6 2 2022-01-06 NaN 2.0
5 2 2022-01-07 11-55-24-33443 3.0