I Have a dataframe as follows:
df = pd.DataFrame({'Key':[1,1,1,1,2,2,2,4,4,4,5,5],
'Activity':['A','A','H','B','B','H','H','A','C','H','H','B'],
'Date':['2022-12-03','2022-12-04','2022-12-06','2022-12-08','2022-12-03','2022-12-06','2022-12-10','2022-12-03','2022-12-04','2022-12-07','2022-12-03','2022-12-13']})
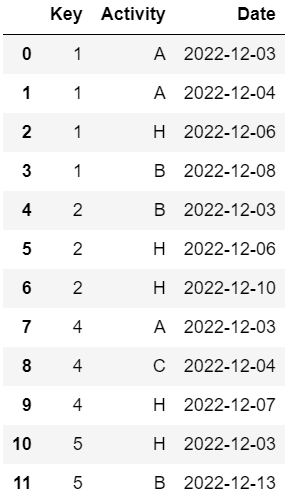
I need to count the activities for each 'Key' that occur before 'Activity' == 'H' as follows:
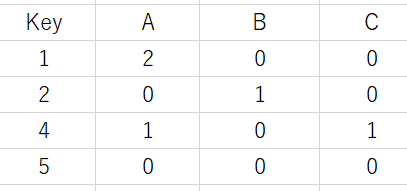
Required Output
My Approach
Sort df by Key & Date ( Sample input is already sorted)
drop the rows that occur after 'H' Activity in each group as follows:
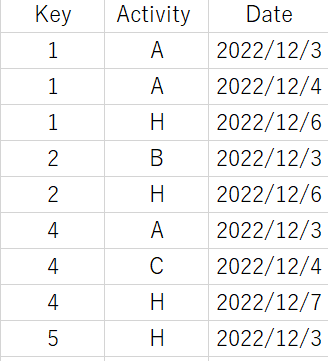
Groupby df.groupby(['Key', 'Activity']).count()
Is there a better approach , if not then help me in code for dropping the rows that occur after 'H' Activity in each group.
Thanks in advance !
CodePudding user response:
You can bring the H dates "back" into each previous row to use in a comparison.
First mark each H date in a new column:
df.loc[df["Activity"] == "H" , "End"] = df["Date"]
Key Activity Date End
0 1 A 2022-12-03 NaT
1 1 A 2022-12-04 NaT
2 1 H 2022-12-06 2022-12-06
3 1 B 2022-12-08 NaT
4 2 B 2022-12-03 NaT
5 2 H 2022-12-06 2022-12-06
6 2 H 2022-12-10 2022-12-10
7 4 A 2022-12-03 NaT
8 4 C 2022-12-04 NaT
9 4 H 2022-12-07 2022-12-07
10 5 H 2022-12-03 2022-12-03
11 5 B 2022-12-13 NaT
Backward fill the new column for each group:
df["End"] = df.groupby("Key")["End"].bfill()
Key Activity Date End
0 1 A 2022-12-03 2022-12-06
1 1 A 2022-12-04 2022-12-06
2 1 H 2022-12-06 2022-12-06
3 1 B 2022-12-08 NaT
4 2 B 2022-12-03 2022-12-06
5 2 H 2022-12-06 2022-12-06
6 2 H 2022-12-10 2022-12-10
7 4 A 2022-12-03 2022-12-07
8 4 C 2022-12-04 2022-12-07
9 4 H 2022-12-07 2022-12-07
10 5 H 2022-12-03 2022-12-03
11 5 B 2022-12-13 NaT
You can then select rows with Date before End
df.loc[df["Date"] < df["End"]]
Key Activity Date End
0 1 A 2022-12-03 2022-12-06
1 1 A 2022-12-04 2022-12-06
4 2 B 2022-12-03 2022-12-06
7 4 A 2022-12-03 2022-12-07
8 4 C 2022-12-04 2022-12-07
To generate the final form - you can use .pivot_table()
(df.loc[df["Date"] < df["End"]]
.pivot_table(index="Key", columns="Activity", values="Date", aggfunc="count")
.reindex(df["Key"].unique()) # Add in keys with no match e.g. `5`
.fillna(0)
.astype(int))
Activity A B C
Key
1 2 0 0
2 0 1 0
4 1 0 1
5 0 0 0
CodePudding user response:
Try this:
(df.loc[df['Activity'].eq('H').groupby(df['Key']).cumsum().eq(0)]
.set_index('Key')['Activity']
.str.get_dummies()
.groupby(level=0).sum()
.reindex(df['Key'].unique(),fill_value=0)
.reset_index())
Output:
Key A B C
0 1 2 0 0
1 2 0 1 0
2 4 1 0 1
3 5 0 0 0
CodePudding user response:
You can try:
# sort by Key and Date
df.sort_values(['Key', 'Date'], inplace=True)
# this is to keep Key in the result when no values are kept after the filter
df.Key = df.Key.astype('category')
# filter all rows after the 1st H for each Key and then pivot
df[~df.Activity.eq('H').groupby(df.Key).cummax()].pivot_table(
index='Key', columns='Activity', aggfunc='size'
).reset_index()
#Activity Key A B C
#0 1 2 0 0
#1 2 0 1 0
#2 4 1 0 1
#3 5 0 0 0