Operating system: CENTOS7.8
Fault background:
Installation deployment process without any errors, but that the installation process has a more impressive, is prompt Avahi service is running, turn off, at that time I ignored installation, the installation process is very smooth, and then directly and running for a period of time is no problem,
This process including restart node 2 examples, a few times are normal, until one article, due to the maintenance need to restart the node 2 operating systems, operating system up, has been unable to start the instance 2, the alert log is as follows:
The 2020-12-18 T14:57:51. 234732 + 08:00
LMS 1:0 GCS we cancelled, closed 0, 0 Xw survived, skipped 0
The 2020-12-18 T14:57:51. 234736 + 08:00
LMS 2:0 GCS we cancelled, closed 0, 0 Xw survived, skipped 0
Set the master node info
The 2020-12-18 T14:58:00. 053624 + 08:00
Submitted all remote - the enqueue requests
The 2020-12-18 T14:58:01. 495578 + 08:00
Dwn - CVTS replayed, VALBLKs dubious
All grantable enqueues granted
Submitted all GCS remote - cache requests - this step will card for a long time, about 30 minutes, the feeling is always in the retry behind (at the node 1 log also supposedly)
The 2020-12-18 T15:09:09. 048173 + 08:00
DIAG (ospid: 128827) waits for the event 'process diagnostic dump' for 0 secs.
The 2020-12-18 T15:09:10. 083280 + 08:00
Errors in the file/u01/app/oracle/diag/RDBMS/former orcl2/trace/orcl2_lmon_128847 TRC:
ORA - 00481: LMON process terminated with error - eventually LMON process will terminate the instance
The 2020-12-18 T15:09:10. 130119 + 08:00
The USER (ospid: 129179) : terminating the instance due to error 481
At the same time, the instances of 1 is normal operation, the alert log of instance 1:
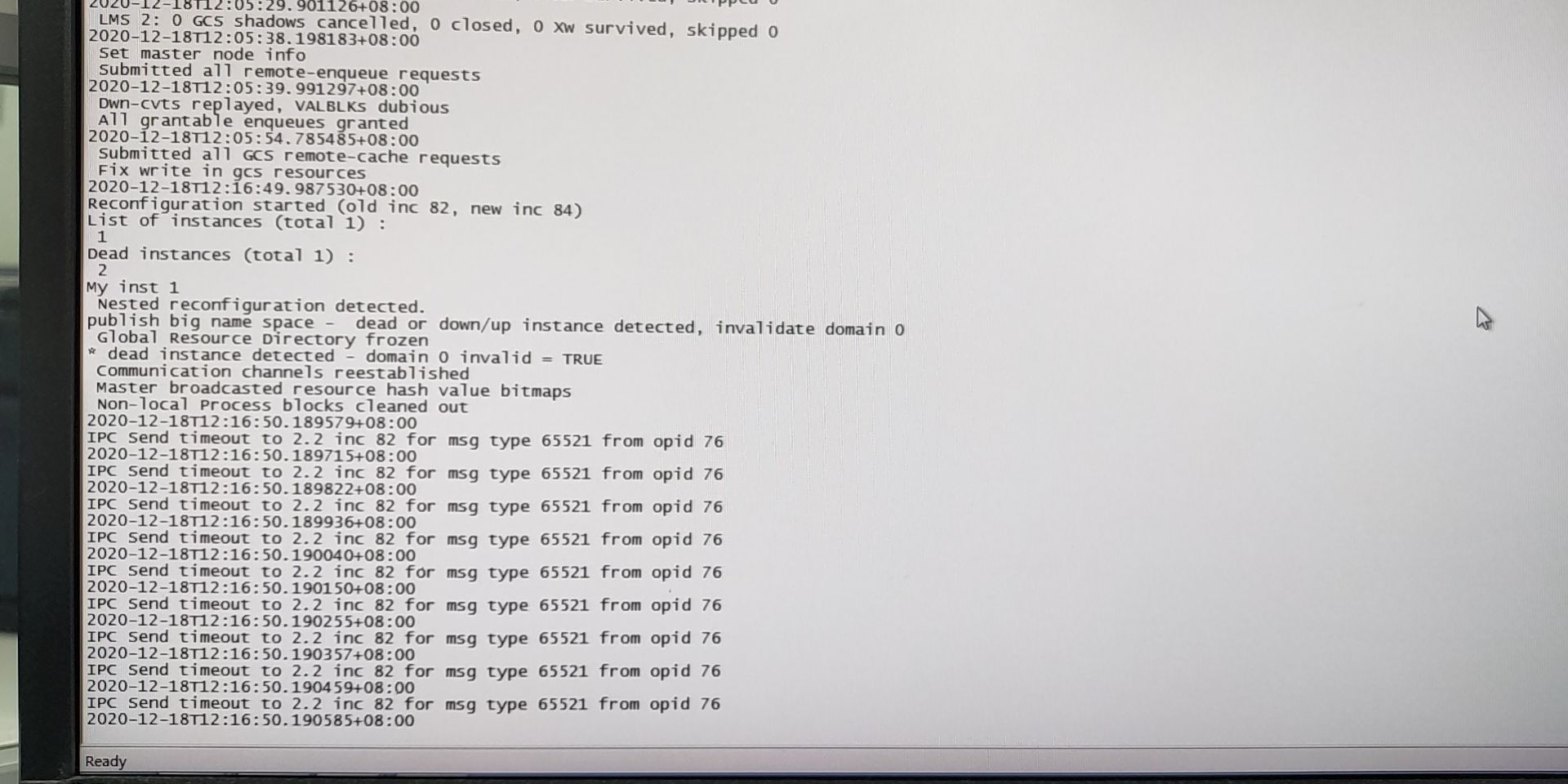
There a lot of IPC Send timeout to 2.2 information, from the point of information, is a node 1 can't get the response node 2, and then after many retries, there appears a large number of IPC Send information, intuition is a heartbeat network appeared abnormal,
At this point, however, two node cluster resource state is normal, including restart node 2 cluster service, also can join normally:
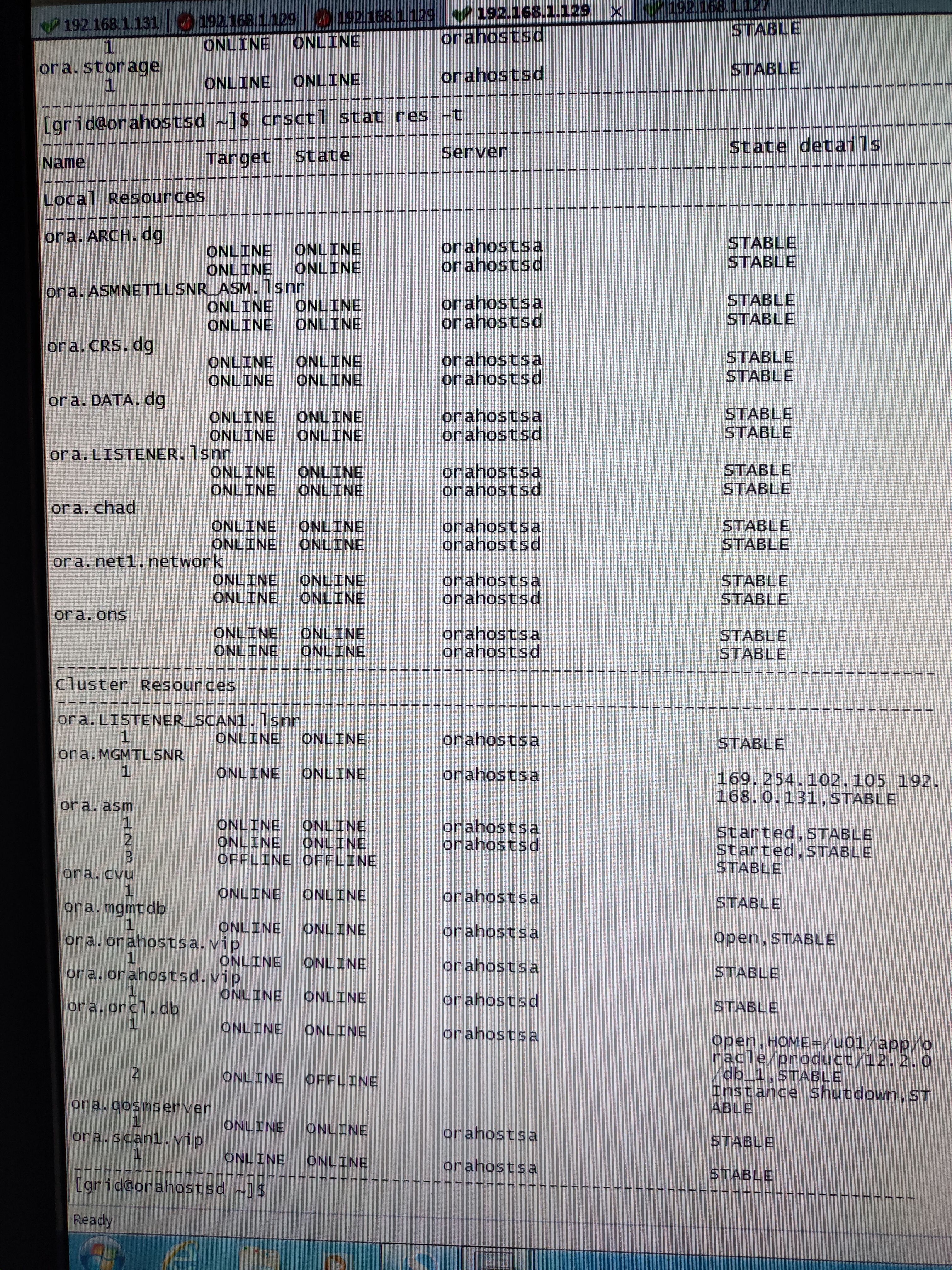
Individual analysis:
This feeling is a heartbeat network problems, but there is no question of ping each other private network, SSH also no problem to each other, and online to see this case: https://www.anbob.com/archives/5052.html I is a little similar to me, the cluster ocssd. The error log
Many of them are the same, it says here to enable the avahi the service lead to abnormal heartbeat network, I check nodes 1 and 2, node 1 is launched the service, I shut down as it suggest (but not restart the operating system), and then restart the node 2 instances, fault error is still the same, another official article: http://blog.sina.com.cn/s/blog_4d22b9720102x8bh.html also said to reboot the avahi services can lead to network card will be abnormal (with I restart the node 2 system match), but the current node 1 can't restart (business), then consult the direction of how to troubleshoot? A similar situation has touched a friend?
In addition the private network and public IP heartbeat is one common switches, private network partitioning the different vlan, I do not know if this have?
CodePudding user response:
From the the problem description, the basic is network problems,Then restart the instance 2 when did see instance haip start?
Subsequent to stop the avahi service first,
In addition, the MOS ORA - 481 found a few bugs associated with DRM, DRM is closed now?
CodePudding user response:
Hello, now I can judge is larger private network out of the question, but I don't know how to confirm, and then the next step, I want to try try change into separate switches, haip whenever I see if there is only one resource, I have seen on both sides of the other normal RAC node to see content is like this: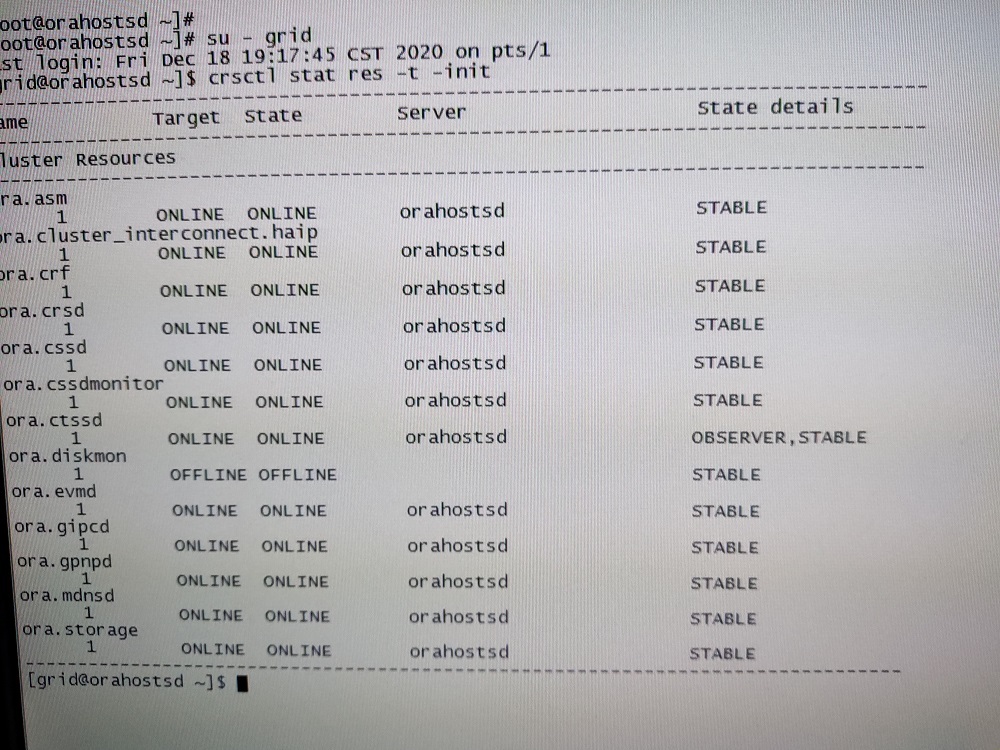
At present two examples avahi services are stopped (node 1 before have this service, has stopped, but did not restart the operating system)
DRM as if did not move, I also checked is there were a few bugs, but if is 11 g version, 12.2.0.1 if no related cases
I here also explain: I set SGA 940 g is larger, so I suspect that the great impact to the network, and on the same switch and gigabit whether to give in to the (when I was installing cluster prompt SSH performance is low, I ignore the installation).