I have a dataframe which contains run-data of testcases. The most important metric in that dataframe is the column 'Elapsed Time', which is a timedelta object that tells the run time of a specific testcase.
The dataset looks like this: (nothing is sorted, even if it might seem so btw)
| Test key | Started At | Finished At | Elapsed Time | Version | |
|---|---|---|---|---|---|
| 0 | TEST-1676 | 2021-06-10 14:40:00 | 2021-06-10 15:24:00 | 0 days 00:44:00 | 8.0.1.0 |
| 1 | TEST-1518 | 2021-06-11 12:14:00 | 2021-06-11 12:36:00 | 0 days 00:22:00 | 8.0.1.0 |
| 2 | TEST-1518 | 2021-06-11 09:29:00 | 2021-06-11 09:44:00 | 0 days 00:15:00 | 8.0.1.0 |
...
| Test key | Started At | Finished At | Elapsed Time | Version | |
|---|---|---|---|---|---|
| 1037 | TEST-1140 | 2018-11-28 09:35:00 | 2018-11-28 10:35:00 | 0 days 01:00:00 | nan |
| 1038 | TEST-1138 | 2018-11-28 10:56:00 | 2018-11-28 11:08:00 | 0 days 00:12:00 | nan |
- What am I doing wrong?
- Why is the sum different when applied to all groups?
- How come that I get a negative timedelta when summerizing?
Edit:
Here is the code, which produces the faulty output for me:
CodePudding user response:
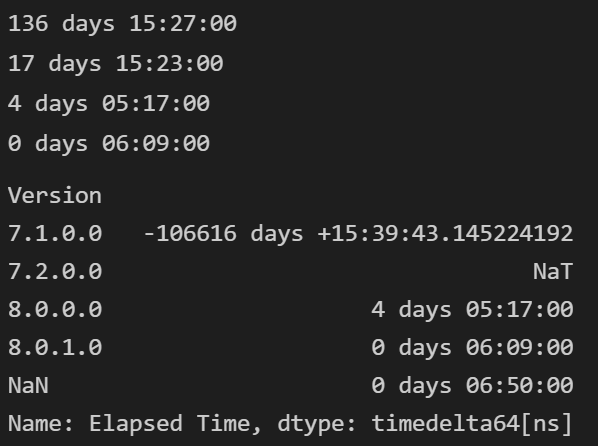
You have 8 rows with NaNs as Version. By defaults, groupby drops the NaNs, thus the missing 6h 50min.
Use:
df_runs.groupby(['Version'], dropna=False)['Elapsed Time'].sum()
output:
Version
7.1.0.0 136 days 15:27:00
7.2.0.0 17 days 15:23:00
8.0.0.0 4 days 05:17:00
8.0.1.0 0 days 06:09:00
NaN 0 days 06:50:00
Name: Elapsed Time, dtype: timedelta64[ns]
CodePudding user response:
After seeing mozways answer and some more comments, it seems he didn't have problems with the data.
I then checked my data for NaN values using:
df_na = df_runs[df_runs.isna().any(axis=1)]
df_na
which returned several rows which didn't have any dates filled in.
That's a failure in the data given, there shouldn't be ANY NaN values in the date columns, because a test-run cannot finish without those values.
However this shouldn't matter for the sum() function, since NaN values are simply ignored. This is shown by using sum on the individual groups, where it works.
Why does this produce faulty values on my machine? - I don't know.
How did I fix it?
Either by dropping the NaN values or replacing them with zero's.
# EITHER: drop NaN values
df_runs = df_runs.dropna()
# OR: replace NaN with Timedelta zero
df_runs['Elapsed Time'] = df_runs['Elapsed Time'].fillna(pd.Timedelta(0))