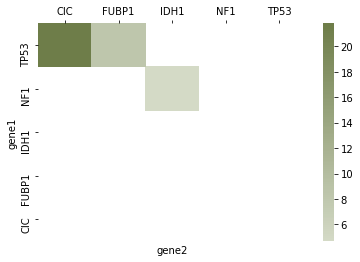I have a pandas dataframe which looks like:
gene1 gene2 pvalue qvalue
TP53. FUBP1 6.381282e-09. 2.435575e-08
TP53. CIC 1.570489e-22. 7.055298e-22
IDH1. NF1 1.946551e-05. 7.116265e-05
I want a matrix as shown below:
So I to plot a matrix which has gene names as rows and columns and colours only those cells for which gene pairs are found in the pandas dataframe above. How can I achieve this in pandas. Insights will be appreciated.
CodePudding user response:
Here is a working version:
import seaborn as sns
# cleanup
df['pvalue'] = df['pvalue'].str[:-1].astype(float)
df['gene1'] = df['gene1'].str[:-1]
idx = sorted(set(df['gene1']).union(df['gene2']))
df2 = (df.pivot(index='gene1', columns='gene2', values='pvalue')
.reindex(index=idx, columns=idx)
)
mask = df2.isna()&np.isnan(df2.T.values) # keep track of NAs on both combinations of genes (A/B and B/A)
df2 = df2.fillna(0)
df2 = df2.values.T # fill matrix A/B → B/A
df2 = df2.mask(mask) # restore NAs
cmap = sns.diverging_palette(323, 101, s=60, as_cmap=True)
ax = sns.heatmap(data=-np.log10(df2), mask=np.triu(df2.values), center=0, cmap=cmap)
ax.invert_yaxis()
ax.xaxis.tick_top()
output: