How does one export the results of a pandas **multi-index dataframe ** to excel using openpyxl with the column headings and index values?
I would assume that I'd need to set index=True within the dataframe_to_rows() method. However, when I do this, it throws a ValueError: stating that it cannot convert IndexLabel values to excel. For example:
ValueError: Cannot convert ('Elf', 'Elrond') to Excel
What I'd expect to be loaded into excel is something similar to this:
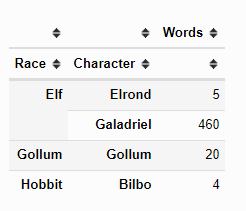
My Current Code
import openpyxl
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from pathlib import Path
multi_df = df.set_index(['Film', 'Chapter', 'Race', 'Character']).sort_index()
subset_df = multi_df.loc[('The Fellowship Of The Ring', '01: Prologue'), :]
# Read in TEMPLATE file from which a copy of the Template will be populated
outfile = 'TEST_Pivot2XL_TEMPLATE.xlsx'
template_filename = 'YYMMDD-YYMMDD_LOTR_TEMPLATE.xlsx'
wb = openpyxl.load_workbook(Path(Path.cwd() / "ReportFiles" / "Summary" / str(template_filename)))
ws = wb["myPivot"]
for r in dataframe_to_rows(subset_df, index=True, header=True):
ws.append(r)
wb.save(file)
NOTE: I have an existing excel template file with an empty Sheet titled "myPivot" that I want to write my pivot table into.
The Dataset I am using is here:
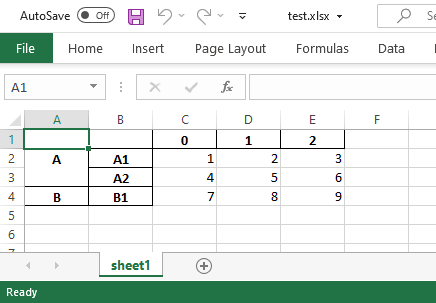
A file named test.xlsx should exist in the working directory for the code to work. Note that it will write to the beginning of the sheet and not append to what is already there.
p.s - the assignment to writer.book and writer.sheets seem useless but the ExcelWriter uses them to figure out which sheets already exist and not write new ones instead.