I have some data that I scrubbed from an offline source using some text recognition software. It looks something like the data below, but less Elvish.
elvish_ring_holders_unclean <- tibble(
name=c("Gandalf", "Galadriel", "Elrond", "Cirdan\n\nGil-Galad"),
city = c("Undying Lands","Lothlorien","Rivendell", "Mithlond\n\nLindon"),
race = c("Maiar", "Elf", "Elf", "Elf\n\nElf"))
The problem for both datasets is that certain rows have been concatenated together with spaces. What I would prefer is something like the data below with each observation having its own row
elvish_ring_holders <- tibble(
name=c("Gandalf", "Galadriel", "Elrond", "Cirdan","Gil-Galad"),
city = c("Undying Lands","Lothlorien","Rivendell", "Mithlond", "Lindon"),
race = c("Maiar", "Elf", "Elf", "Elf", "Elf"))
So far, I have tried a tidyr::separate_rows approach
elvish_ring_holders %>%
separate_rows(name, sep = "\n\n") %>%
separate_rows(city, sep = "\n\n") %>%
separate_rows(race, sep = "\n\n") %>%
distinct()
But, I end up with a dataset where Gil-Galad and Cirdan both have two observations with two different cities with one true city and one false city.
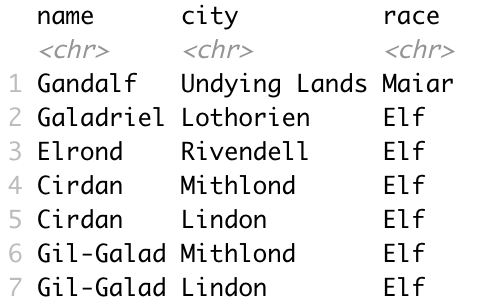
In my exterior data, my race variable also can duplicate in this way and the data has more observations. What I am looking for is some method of separating rows that can separate once across multiple cols.
CodePudding user response:
Instead of separating each column on it's own do them all in one go.
elvish_ring_holders_unclean %>%
separate_rows(everything(), sep = "\n\n")
| name | city | race | |
|---|---|---|---|
| 1 | Gandalf | Undying Lands | Maiar |
| 2 | Galadriel | Lothlorien | Elf |
| 3 | Elrond | Rivendell | Elf |
| 4 | Cirdan | Mithlond | Elf |
| 5 | Gil-Galad | Lindon | Elf |