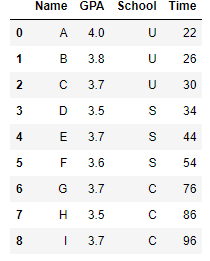
Assume I am merging a panda data frame iteratively in a loop but after two or three iterations panda repeat the column name for example consider the following example where I am merging the columns iteratively but without loop for simplicity:
A= {'Name':['A','B','C'],'GPA':[4.0,3.80,3.70], 'School':['U','U','U'], 'Time':[22,26,30]}
A1 = pd.DataFrame(A)
B= {'Name':['D','E','F'],'GPA':[3.50,3.70,3.60], 'School':['S','S','S'],'Time':[34,44,54]}
B1 = pd.DataFrame(B)
C= {'Name':['G','H','I'],'GPA':[3.70,3.50,3.70], 'School':['C','C','C'],'Time':[76,86,96]}
C1 = pd.DataFrame(C)
L= [A1,B1,C1]
comb = A1
for ii in L[1:]:
comb = pd.concat([comb,ii],ignore_index=True)
comb
B = pd.merge(comb, comb, on=['Name','GPA'])
C = pd.merge(B, comb, on=['Name','GPA'])
D = pd.merge(C, comb, on=['Name','GPA'])
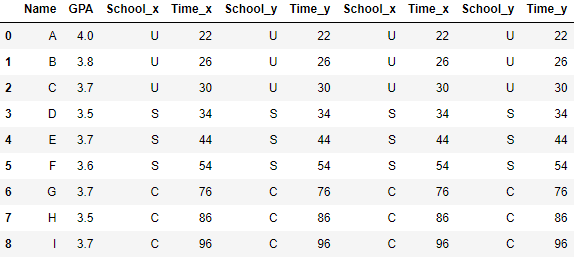
You see Panda is repeating the School_x and School_y name twice, is there anyway to change it to School_x and School_y, School_z and School_t. I am not talking about renaming it afterward but forcing the merge to choose new column names for columns that are not the same. Otherwise how one can distinguish the data frames with 1000 columns and imagine 500 have the same column names.
Update: Above was just an example assume you are merging the multiple data frames in loop like this:
for ii in list:
df = df.merge(A,on = 'some column', how = 'outer')
Then how do you change the column name iteratively it seems to me every time the same columns will be repeated even with the suffix.
CodePudding user response:
Try changing the suffixes argument to a tuple of ('_z', '_t'):
B = pd.merge(comb, comb, on=['Name','GPA'])
C = pd.merge(B, comb, on=['Name','GPA'])
D = pd.merge(C, comb, on=['Name','GPA'], suffixes=('_z', '_t'))
>>> D
Name GPA School_x Time_x School_y Time_y School_z Time_z School_t Time_t
0 A 4.0 U 22 U 22 U 22 U 22
1 B 3.8 U 26 U 26 U 26 U 26
2 C 3.7 U 30 U 30 U 30 U 30
3 D 3.5 S 34 S 34 S 34 S 34
4 E 3.7 S 44 S 44 S 44 S 44
5 F 3.6 S 54 S 54 S 54 S 54
6 G 3.7 C 76 C 76 C 76 C 76
7 H 3.5 C 86 C 86 C 86 C 86
8 I 3.7 C 96 C 96 C 96 C 96
>>>
As in the pd.merge documentation:
Parameters:
...
...suffixes: list-like, default is (“_x”, “_y”)
A length-2 sequence where each element is optionally a string indicating the suffix to add to overlapping column names in left and right respectively. Pass a value of None instead of a string to indicate that the column name from left or right should be left as-is, with no suffix. At least one of the values must not be None.
... ...
Edit:
For the recent update on the question, try creating an iterator and with next.
Much better with functools.reduce:
from functools import reduce
from string import ascii_lowercase
it = iter(ascii_lowercase)
print(reduce(lambda x, y: pd.merge(x, y, on=['Name','GPA'], suffixes=('_' next(it), '_' next(it))), [comb for _ in range(4)]))
Output:
Name GPA School_a Time_a School_b Time_b School_e Time_e School_f Time_f
0 A 4.0 U 22 U 22 U 22 U 22
1 B 3.8 U 26 U 26 U 26 U 26
2 C 3.7 U 30 U 30 U 30 U 30
3 D 3.5 S 34 S 34 S 34 S 34
4 E 3.7 S 44 S 44 S 44 S 44
5 F 3.6 S 54 S 54 S 54 S 54
6 G 3.7 C 76 C 76 C 76 C 76
7 H 3.5 C 86 C 86 C 86 C 86
8 I 3.7 C 96 C 96 C 96 C 96
As you can see I create a list comprehension with [comb for _ in range(4)], that would loop and merge 4 times, to change the number of times just change the number i.e. [comb for _ in range(10)].
For a function:
from functools import reduce
from string import ascii_lowercase
def cumulative_merge(df, n):
it = iter(ascii_lowercase)
return reduce(lambda x, y: pd.merge(x, y, on=['Name','GPA'], suffixes=('_' next(it), '_' next(it))), [comb for _ in range(n)])
Execution:
print(cumulative_merge(df, 4))
Output:
Name GPA School_a Time_a School_b Time_b School_e Time_e School_f Time_f
0 A 4.0 U 22 U 22 U 22 U 22
1 B 3.8 U 26 U 26 U 26 U 26
2 C 3.7 U 30 U 30 U 30 U 30
3 D 3.5 S 34 S 34 S 34 S 34
4 E 3.7 S 44 S 44 S 44 S 44
5 F 3.6 S 54 S 54 S 54 S 54
6 G 3.7 C 76 C 76 C 76 C 76
7 H 3.5 C 86 C 86 C 86 C 86
8 I 3.7 C 96 C 96 C 96 C 96