I have a sample dataframe as shown below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID':['A','A','A','A','A','A','A','A','A','C','C','C','C','C','C','C','C'],
'Week': ['Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2','Week3',
'Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2'],
'Risk':['High','','','','','','','','','High','','','','','','',''],
'Testing':[NaN,'Pos',NaN,'Neg',NaN,NaN,NaN,NaN,'Pos', NaN,
NaN,NaN,'Negative',NaN,NaN,NaN,'Positive'],
'Week1_adher':['Yes',NaN,NaN,NaN,NaN,NaN,NaN,NaN,NaN,'No',NaN,NaN,NaN,NaN,NaN,NaN,NaN],
'Week2_adher':['No',NaN,NaN,NaN,NaN,NaN,NaN,NaN,NaN,'No',NaN,NaN,NaN,NaN,NaN,NaN,NaN],
'Week3_adher':['No',NaN,NaN,NaN,NaN,NaN,NaN,NaN,NaN,'No',NaN,NaN,NaN,NaN,NaN,NaN,NaN]}
df1 = pd.DataFrame(data)
df1
The final dataframe has to be such that there has to be rows as many number of weeks for each participant. After conversion of week columns to rows, it should have its corresponding values.
Also, the number of notna values in 'Testing' column for each week for each participant should be added to the '#of test" values.
The final dataframe should look like the image given below.
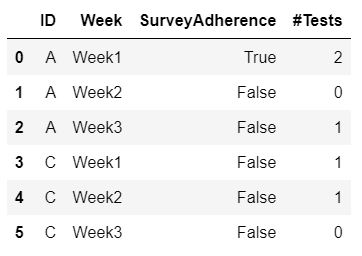
CodePudding user response:
Preprocess your dataframe by creating the two new columns then group by ID and Week and finally aggregate new columns:
df1['SurveyAdherence'] = df1.filter(regex=r'Week\d _adher').eq('Yes').any(axis=1)
df1['#Tests'] = df1['Testing'].notna()
mi = pd.MultiIndex.from_product([df1['ID'].unique(), df1['Week'].unique()],
names=['ID', 'Week'])
out = df1.groupby(['ID', 'Week']) \
.agg({'SurveyAdherence': 'max', '#Tests': 'sum'}) \
out = out.reindex(mi) \
.fillna({'SurveyAdherence': False, '#Tests': 0}) \
.astype({'SurveyAdherence': bool, '#Tests': int}) \
.reset_index()
Output:
>>> df1
ID Week SurveyAdherence #Tests
0 A Week1 True 2
1 A Week2 False 0
2 A Week3 False 1
3 C Week1 False 1
4 C Week2 False 1
5 C Week3 False 0