I have a sample dataframe as given below.
import pandas as pd
data = {'ID':['A','A','A','A','A','A','A','A','A','C','C','C','C','C','C','C','C'],
'Week': ['Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2','Week3',
'Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2'],
'Risk':['High','','','','','','','','','High','','','','','','',''],
'Testing':['','Pos','','Neg','','','','','Pos', '', '','','Neg','','','','Pos'],
'Week1_adher':['','','','','','','','','', '','','','','','','',''],
'Week2_adher':['','','','','','','','','','','','','','','','',''],
'Week3_adher':['','','','','','','','','','','','','','','','','']}
df1 = pd.DataFrame(data)
df1
Now I want to calculate adherence for each participant for each week. Its calculation is given as follows: If a participant has 2 or more entries(either positive/negative)in testing column for a week, then Adherence for that week is 'Yes' else its 'No'
Example, For participant A, week 1_adherence is 'Yes' because it has 2 entries in Testing column for Week1. Week2_adherence is 'No'
And I want the adherence results for all week to be displayed in the first row of each participant.
The final dataframe should like the image given below.
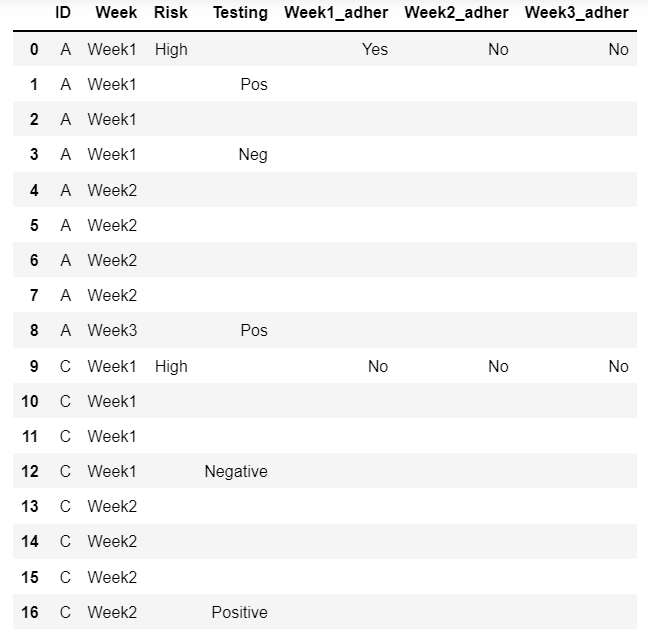
I have been stuck on this for quite some time. Any help is greatly appreciated. Thank you.
CodePudding user response:
Try:
adher = (df1.Testing.ne('') # check for non-empty string
.groupby([df1.ID, df1.Week]) # groupby ID and week
.sum().ge(2) # count and check >= 2
.unstack(fill_value=False)
.replace({True:'Yes', False:'No'})
.add_suffix('_adher')
)
# the first lines
mask = ~df1['ID'].duplicated()
df1.loc[mask, adher.columns] = adher.loc[df1.loc[mask,'ID']].values
Output:
ID Week Risk Testing Week1_adher Week2_adher Week3_adher
0 A Week1 High Yes No No
1 A Week1 Pos
2 A Week1
3 A Week1 Neg
4 A Week2
5 A Week2
6 A Week2
7 A Week2
8 A Week3 Pos
9 C Week1 High No No No
10 C Week1
11 C Week1
12 C Week1 Negative
13 C Week2
14 C Week2
15 C Week2
16 C Week2 Positive